
後Scaling Law時代,需要一份向量資料庫的琅琊榜
鳳凰科技 2024-12-13 01:35:45 1

編輯 | 程茜
Scaling Law的時代,真的結束了。
最先發出警告的,來自ChatGPT背後的頭號功臣Ilya Sutskever。
路透社的官方採訪中他直言不諱“ results from scaling up pre-training – the phase of training an AI model that uses a vast amount of unlabeled data to understand language patterns and structures – have plateaued.”
——大資料訓練,帶來的AI智慧程度提升已達階段性瓶頸。
但“Scaling the right thing matters more now than ever.”
——選對正確的方向,比過去任何時代,都要更加重要與迫切。但是,風向突變,未來大模型到底要Scaling什麼?
不同於技術前沿的恐慌四處瀰漫,相比尋找最頂級的大模型,業界已經早早將目光轉向了通往智慧的另一條捷徑——向量資料庫。
一、源起:AI時代的資料庫機會
“如果說算力是火箭的機體,那麼演算法是控制系統,資料是燃料,雖然每一輪計算機技術的革命都是從硬體開始,然後是演算法的進步,但資料才是最核心、最有價值的資源。”“未來這個賽道,將跑出估值至少百億美金的公司。”
說話的是星爵,向量資料庫創業公司Zilliz的創始人。
2017大模型開山之作Transformer 在論文《Attention is All You Need》中提出的同期,在Oracle工作了七年之久的他開啟了人生中的第一次創業——面向未來,做一款專屬於AI時代的資料庫產品。
那是在大模型還沒等來ChatGPT的漫長蟄伏期,傳統CV、NLP卻在一輪輪天價融資與遲遲不見蹤影的市場化夾縫中,慢慢走向泡沫破裂的時刻。
生存環境變得惡劣,遭遇的拷問也越來越嚴苛:資料庫是巨頭的遊戲,創業公司憑什麼參與?AI時代,為什麼需要新的資料庫?這個資料庫,又與傳統資料庫有什麼區別?
回答這一切問題的前提,是對產業發展趨勢進行足夠清晰的梳理。
首先,AI時代,我們使用的資料本身有了什麼變化?
答案是從結構化資料,向非結構化演變。相比傳統的結構化資料,其格式更加不固定,有圖片、有音訊、有影片、有文字、日誌……而他們共同的特點,就是資料結構不規則或不完整,沒有預定義的資料型別,難以用資料庫二維表來表現。與此同時,這些資料本身所涵蓋的資訊密度更大,但如何提取背後隱含的資訊,往往需要特殊的處理與分析,相對應的如何對其進行檢索與描述也是行業面臨的困境之一。此外,伴隨移動網際網路的發展,IDC統計發現,非結構化資料的數量正在飛速增長,佔據了全人類資料總量的80%之多。
痛點眾多,但需求同樣迫切。算力和演算法是大模型通往終局的耀眼明珠,但資料的質量、規模和多樣性,則直接決定了所能挖掘到的資訊的價值深度和廣度。如何滿足這一市場需求,這是面向AI時代的資料庫的機會,也是創業公司挑戰巨頭的底氣所在。
但這個產品應該如何建構呢?星爵腦中冒出了一個前所未有的形態——向量資料庫。
早在20世紀70年代末至90年代中期,人工智慧浪潮尚在第二階段,那時的產業就已經有了初步的非結構化資料利用思路,將文字、圖片利用演算法,進行特徵提取,然後將其轉化為空間中的不同向量維度進行表示。比如一朵玫瑰花的照片,在向量空間中,可以被描述為:圖片格式、植物、紅色、愛情、保質期短、花卉等幾百上千個維度,這些維度全部以數字與程式碼的形式呈現給計算機,在此基礎上,人工智慧透過暴力的學習,進而掌握玫瑰花的圖片識別能力。
如果將這一過程進行產品化升級,也就奠定了向量資料庫的產品雛形。由此,在星爵的帶領下,Zilliz敲下了全世界向量資料庫的第一行程式碼,全世界第一個向量資料庫產品Milvus正式誕生了。
在此之後,2019年10月15日,Zilliz正式宣佈將 Milvus在GitHub上開源,使用者只需一臺伺服器,區區十行程式碼,就可以輕鬆實現十億相簿的以圖搜圖,響應時間僅為數百毫秒。
在此之後以圖搜圖、影片搜尋、企業知識庫構建相繼爆火,Milvus在Github上的star短短三年,就突破了一萬的數量,但此時距離向量資料庫真正在大眾範圍內出圈,還差一把火。
二、爆發:LLM陰雲籠罩,RAG外掛破局
如果科技產業有自己的編年體史書,關於2022-2024這三年的瘋狂,大概可以被這樣概括:
2022年年終,ChatGPT橫空出世,大模型火遍全球。
2023年,百模齊發,英偉達稱王;然而,如何解決大模型幻覺,卻始終是圍繞在大模型頭頂,一朵揮之不去的陰雲。
2024年,OpenAI內亂,Scaling Law觸頂成為大模型落地的第二朵陰雲,大模型的本質是有失真壓縮的觀點被越來越多的人認同。
如何破局?
RAG成為業內公認的解決方案。
但什麼是RAG?
翻譯成中文,就是檢索增強生成。
具體來說,一個典型的RAG框架可以分為檢索器(Retriever)和生成器(Generator)兩部分,檢索過程包括為資料(如Documents)做切分、嵌入向量(Embedding)、並構建索引(Chunks Vectors),再透過向量檢索以召回相關結果,而生成過程則是利用基於檢索結果(Context)增強的Prompt來啟用LLM以生成回答(Result)。
其中,檢索系統透過將特定領域知識、實時更新資訊等大模型所不具備的內容進行向量化並儲存,可以以“外掛”的形式補足了大模型的知識短板;而生成模型則能夠靈活地構建回答,並融入更廣泛的語境和資訊。
而作為RAG檢索系統的核心,向量資料庫也從2023年起,成為各大企業大模型落地過程中的基礎應用工具。甚至就連Open AI,也是向量資料庫的資深擁躉,早在2023年3月,OpenAI就官宣, 透過chatgpt-retrieval-plugin 外掛整合向量資料庫,是大模型產品形成長期記憶一個必不可少的環節。
也是自這一天起,向量資料庫平靜已久的市場瞬間沸騰,成為大模型產業最重要的基礎設施之一:不僅這一年的OpenAI 釋出會與英偉達GTC大會上,老牌玩家Zilliz先後被列入官方外掛庫並受邀上臺演講,僅僅一個多月,數十億熱錢就在一級市場湧入向量資料庫賽道。追隨熱度,一度有企業靠著概念就將公司估值推升至 數十億,魔改ClickHouse 、 HNSWlib加上向量檢索封裝就緊急推出向量資料庫產品的玩家更是多如過江之鯽。而Zilliz2019年開源的向量資料庫Milvus在GitHub的Star數,也在2023至2024年期間,迅速從一萬增長至三萬。
但向量資料庫之於大模型,能力僅限於此嗎?
答案是否定的。
在解決了大模型的幻覺問題之後,大模型的第二朵陰雲,在2024年悄然浮現。
這一年,以Ilya Sutskever為代表,一眾大模型頂級研發大牛逐漸發覺,大模型的Scaling Law效率正逐漸變得越來越低,與此同時,如果保持如今的引數膨脹效率,預計在 2028 年左右,全世界公域網際網路中的資料儲量將被全部利用完。
大模型幾乎將所有公域的知識學習殆盡,但為什麼還未實現真正意義上的通用人工智慧?
大模型剛剛興起之時,業內一度對大模型的認知是大模型是現實世界的無失真壓縮編碼,因此只要大模型學習足夠多的知識,就能還原真實的世界,像現實世界中的人類一樣聰明,甚至透過還原真實世界,可以發掘其背後潛在的執行規律。
如今,隨著Scaling Law放緩,越來越多的人開始意識到,大模型的壓縮本質,是一種有失真壓縮。在學習網際網路的各種資訊之時,大模型往往只能透過內容的組合方式、語法規則等維度,去對資訊進行高度的凝練與規則提取,而這個壓縮過程,往往伴隨的,就是細節的丟失,知識體系的簡化、以及長尾知識的空白。如果以這種缺失細節與深度邏輯的演算法去進行推理,結果就會類似我們古代成語中的“按圖索驥”,以抽象的高額頭、大眼睛、粗四肢為特徵,最終找到的可能不是千里馬,而是完全符合標準的蛤蟆。
答案依舊是向量資料庫與RAG。向量資料庫不僅支援對資料的更多維度解構,同時也可以對細節進行更高程度的還原,並對長尾知識進行儲存,基於此構建的RAG,可以很好的彌補大模型對真實世界有失真壓縮帶來的缺陷。比如在影象領域,今年爆火的ColPali RAG、iRAG、VisRAG,都是其中代表。
也是因此,今年年底,在Menlo Ventures對600家美國企業進行調研之後發現,企業 AI 的部署落地中,RAG佔比從2023年的31%,到2024年上升到 51%,與之形成鮮明對比,生產環境中,僅有9%的生產模型採用微調方式進行模型部署。
向量資料庫與RAG,幾乎成為了大模型落地的預設最強外掛。
但不同於C端使用者可以在office辦公套件與國產的WPS之間靈活切換;由於關係到企業隱私資料的管理,以及頂層業務的搭建,B端對資料庫的選擇往往慎之又慎,企業一旦找到合適的產品,就會受限於資料遷移成本高、與現有系統整合緊密、運維和管理成本高等綜合因素,在很長一段時間內不會進行更換。資料庫一用四十年,產品生命週期比程式設計師職業週期還長的情況,在這一行業並不罕見。
舉個簡單例子,在金融賽道,大模型除了需要掌握公開的知識,還需要大規模、多樣化、高質量、實時的使用者交易記錄、信用記錄、消費行為等資料,才能準確預測客戶的信用風險和投資偏好,並基於此為投資者提供更全面、準確的投資建議;在醫療行業,在疾病診斷中,向量資料庫能夠提供準確詳細的病歷資料、檢驗檢查結果等資料,是大模型準確判斷疾病型別、嚴重程度和制定治療方案的關鍵。
也是因此,如何選擇合適的向量資料庫,也成為了困擾無數大模型應用開發者的頭疼問題。
三、激戰:向量資料庫的琅琊榜
不久前,全球知名獨立研究機構Forrester釋出《2024年第三季度向量資料庫供應商Wave報告》,正式對向量資料庫市場的江湖座次,用一張琅琊榜給出了自己的評判。
在這份報告中,Forrester選擇了14家向量資料庫供應商,對其產品能力、商業策略、市場表現為核心的25項評估標準進行打分,參賽選手既包括AWS等知名大廠,也有甲骨文、MangoDB等老牌資料庫玩家,以及Zilliz等向量資料庫代表玩家。
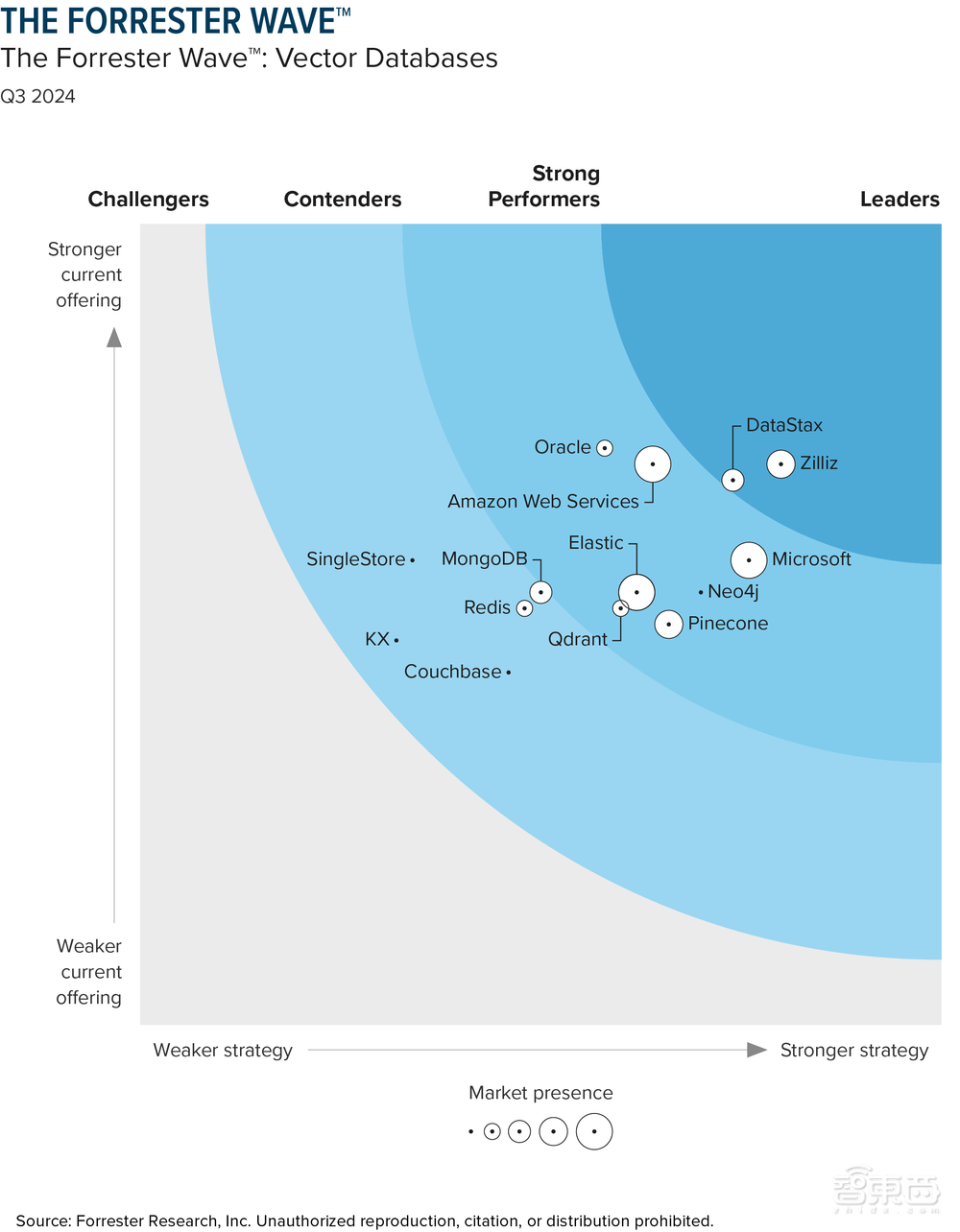
在這張表中,橫軸代表玩家的戰略(strategy),對應企業的戰略創新能力,縱軸代表當前產品的能力(current offering),圓圈的大小代表企業的市場份額(market presence)。三個半圓的象限,則是Forrester報告設定的領導者(leaders)、表現強勁(strong performers)、競爭者(contenders)三大玩家梯隊。
透過這張表,不難發現,一方面AWS等雲服務巨頭掌握了市場相當一部分使用者數,但與此同時,Zilliz為代表的創業公司,也首次衝進領導者象限,成為這個市場在產品以及技術創新方向的領頭羊。緊隨其後,第二梯隊玩家同樣表現強勁,這也是所含企業最多的層級,包括甲骨文等7家供應商。但相比於領導者,這些供應商在某些方面存在明顯不足,如微軟缺乏高階向量功能、甲骨文的解決方案尚未成熟……第三梯隊的競爭者相比上述兩類,綜合表現較弱,其產品大多不成熟或者缺少部分重要功能。
更具體拆解來看,報告中認為,企業在選擇向量資料庫時應該重點關注三個主要方面:支援廣泛的核心向量功能、簡化向量的資料管理、以高效形式實現效能與規模的交付。
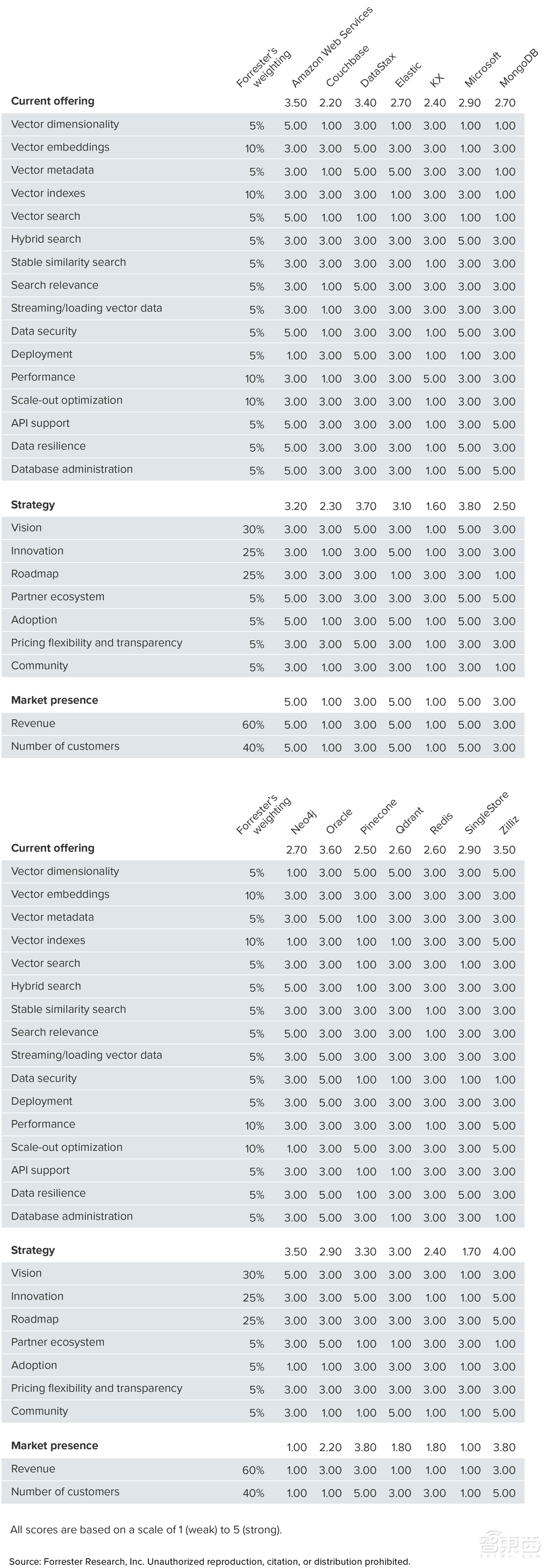
而想要做到這些,向量資料庫需要構建包括向量索引、後設資料管理、向量搜尋和混合搜尋等在內的全面功能,同時為了保證企業互動友好、便利,向量資料庫需要兼顧廣泛資料管理功能和簡化部署、快速開發的能力。此外,面對不斷膨脹的大模型規模,向量資料庫在儲存和處理數千萬到上億個向量時,還應能保證查詢速度,並根據工作負載要求進行彈性擴充套件和收縮。
以此次領導者向量資料庫企業Zilliz為例,在具體得分上,Forrester在向量維度、向量索引、效能、可擴充套件性方面給這家企業打出了高分,指出其不僅擅長管理大量向量資料,同時兼具最佳化的儲存、高效管理和搜尋功能。
比如在可擴充套件性層面,透過這份公開的產品對比不難發現,相比傳統資料庫玩家,Milvus透過支援磁碟索引,可以實現更輕鬆擴充套件和更合理的資源分配。通常來說,磁碟索引可以將部分資料儲存在磁碟上,僅在需要時載入到記憶體中;支援Partition/Namespace/邏輯分組,則可以將資料按照特定的規則或屬性進行劃分,同時根據重要性或訪問頻率分配不同資源。
此外,Milvus支援的索引型別多達11種,這也使其更能適應不同資料特點,並提升查詢準確性。

▲Milvus和MongoDB向量資料庫產品可擴充套件性對比
那麼一個新的問題來了,一家創業公司,如何在巨頭的包圍中層層突圍,打造大模型時代的新型基礎設施?
四、突圍:創業公司如何打造大模型時代的新型基礎設施
一定程度上,Zilliz的成功,是一個大模型時代,創業公司從巨頭射程突圍,野蠻生長的範例。這背後,既有歷史程序的助推,同樣離不開企業自身技術遠見與長期主義堅持。
於時代背景而言,2022年底釋出的ChatGPT,是這家企業從低調蟄伏到一鳴驚人的拐點。大模型的普及,加速讓非結構化資料的處理成為主流,向量資料庫自此闖入聚光燈下。
恰逢其時,傳統的資料庫企業,儘管擁有更好的技術基礎、資料資源與客戶基礎,然而其為傳統倒排索引而構建的的產品形態,對於需要基於密集向量檢索、資料規模極速膨脹的大模型而言,原本的優勢被重新翻譯為在向量檢索上的搜尋與效能不足。與之形成對比,專業向量資料庫不僅能夠在毫秒級時間內完成上億個目標的檢索與召回;更能透過分散式架構與先進儲存技術,可以在不影響系統效能的前提下,實現從處理小規模向量資料,到支援百億甚至千億級向量資料的平滑過渡。
而與同行的專業向量資料庫玩家相比,Zilliz最大的優勢則在於時間積累起的生態護城河。與多數玩家2023年才趕鴨子上架式一股腦湧入向量資料庫不同,Zilliz是唯一一家在2019年就推出產品化開源向量資料庫的玩家。而對於資料庫這樣一個強調生態效應的市場,五年足以構建起一堵足夠寬厚的技術與行業認知組建起的銅牆鐵壁。在對手還在使用開源演算法進行產品封裝之時,Zilliz不僅有Github 3W star的開源向量資料庫Milvus,同時還推出了商業化產品Zilliz Cloud,為使用者提供百億級向量資料毫秒級檢索能力、開箱即用的向量資料庫服務。
與此同時,大模型的快速普及,也為無數Zilliz這樣的中間層玩家,帶來了前所未有的全球化機遇。不同於老一代網際網路企業的出海敘事,亦或是copy to China、copy from China,Zilliz從成立第一天,就面向全球市場,其商業化程序也透過藉助AWS這樣的雲服務巨頭,實現了全球化擴張,讓使用者可以基於Bedrock+Zilliz Cloud構建一整套完整的RAG應用、以圖搜圖系統、演算法推薦系統等,加速企業的大模型落地。
在這一過程中,Zilliz不僅在全球範圍內積累了上萬企業級使用者,產品更是被廣泛應用於圖片檢索、影片分析、自然語言理解、推薦系統、定向廣告、個性化搜尋、智慧客服、欺詐檢測、網路安全和新藥發現等各個領域,完成從新興玩家到大模型基礎設施的進化。
當時代的風口來臨,參與其中,每個人都能聽到風的聲音,但真正穿越週期,走出巨頭與時代突圍,長期主義才是唯一的答案。