
26歲OpenAI舉報人疑自殺!死前揭ChatGPT訓練黑幕
鳳凰科技 2024-12-15 01:31:51 1

新智元報道
編輯:Aeneas 好睏
【新智元導讀】26歲的OpenAI吹哨人,在發出公開指控不到三個月,被發現死在自己的公寓中。法醫認定,死因為自殺。那麼,他在死前兩個月發表的一篇博文中,都說了什麼?
就在剛剛,訊息曝出:OpenAI吹哨人,在家中離世。
曾在OpenAI工作四年,指控公司侵犯版權的Suchir Balaji,上月底在舊金山公寓中被發現死亡,年僅26歲。
舊金山警方表示,11月26日下午1時許,他們接到了一通要求檢視Balaji安危的電話,但在到達後卻發現他已經死亡。

這位吹哨人手中掌握的資訊,原本將在針對OpenAI的訴訟中發揮關鍵作用。
如今,他卻意外去世。
法醫辦公室認定,死因為自殺。警方也表示,「並未發現任何他殺證據」。
他的X上的最後一篇帖子,正是介紹自己對於OpenAI訓練ChatGPT是否違反法律的思考和分析。
他也強調,希望這不要被解讀為對ChatGPT或OpenAI本身的批評。

如今,在這篇帖子下,網友們紛紛發出悼念。

Suchir Blaji的朋友也表示,他人十分聰明,絕不像是會自殺的人。
吹哨人警告:OpenAI訓練模型時違反原則
Suchir Balaji曾參與OpenAI參與開發ChatGPT及底層模型的過程。
今年10月發表的一篇博文中他指出,公司在使用新聞和其他網站的資訊訓練其AI模型時,違反了「合理使用」原則。
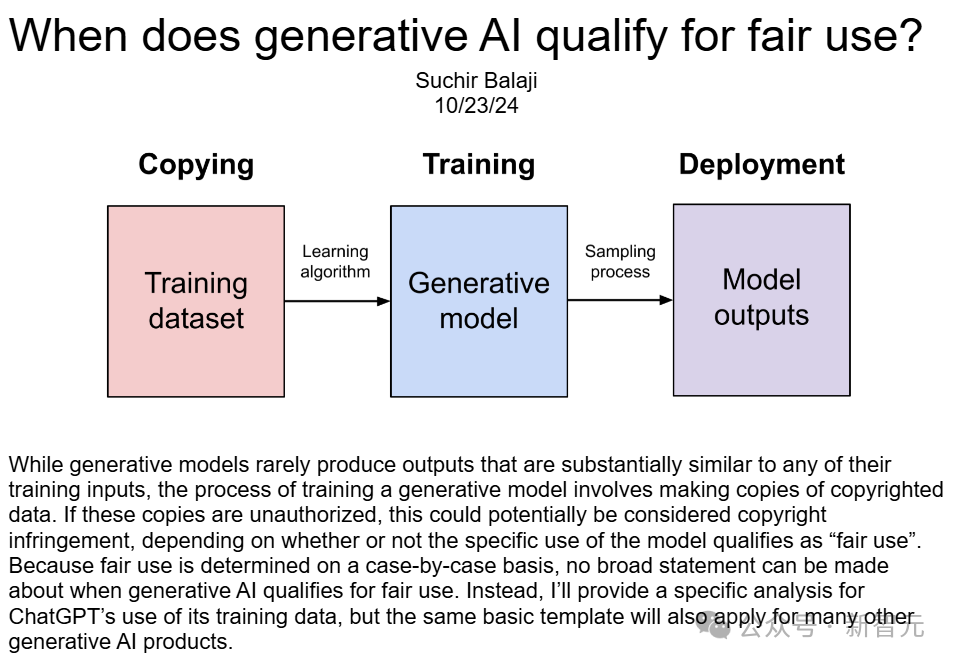
博文地址:https://suchir.net/fair_use.html
然而,就在公開指控OpenAI違反美國版權法三個月之後,他就離世了。
為什麼11月底的事情12月中旬才爆出來,網友們也表示質疑
其實,自從2022年底公開發布ChatGPT以來,OpenAI就面臨著來自作家、程式設計師、記者等群體的一波又一波的訴訟潮。
他們認為,OpenAI非法使用自己受版權保護的材料來訓練AI模型,公司估值攀升至1500億美元以上的果實,卻自己獨享。
為此,《水星新聞報》《紐約時報》等多家報社,都在過去一年內對OpenAI提起訴訟。
今年10月23日,《紐約時報》發表了對Balaji的採訪,他指出,OpenAI正在損害那些資料被利用的企業和創業者的利益。
「如果你認同我的觀點,你就必須離開公司。這對整個網際網路生態系統而言,都不是一個可持續的模式。」
一個理想主義者之死
Balaji在加州長大,十幾歲時,他發現了一則關於DeepMind讓AI自己玩Atari遊戲的報道,心生嚮往。
高中畢業後的gap year,Balaji開始探索DeepMind背後的關鍵理念——神經網路數學系統。
Balaji本科就讀於UC伯克利,主修電腦科學。在大學期間,他相信AI能為社會帶來巨大益處,比如治癒疾病、延緩衰老。在他看來,我們可以創造某種科學家,來解決這類問題。

2020年,他和一批伯克利的畢業生們,共同前往OpenAI工作。

然而,在加入OpenAI、擔任兩年研究員後,他的想法開始轉變。

在那裡,他被分配的任務是為GPT-4收集網際網路資料,這個神經網路花了幾個月的時間,分析了網際網路上幾乎所有英語文字。
Balaji認為,這種做法違反了美國關於已發表作品的「合理使用」法律。今年10月底,他在個人網站上釋出一篇文章,論證了這一觀點。
目前沒有任何已知因素,能夠支援「ChatGPT對其訓練資料的使用是合理的」。但需要說明的是,這些論點並非僅針對ChatGPT,類似的論述也適用於各個領域的眾多生成式AI產品。

根據《紐約時報》律師的說法,Balaji掌握著「獨特的相關檔案」,在紐約時報對OpenAI的訴訟中,這些檔案極為有利。
在準備取證前,紐約時報提到,至少12人(多為OpenAI的前任或現任員工)掌握著對案件有幫助的材料。
在過去一年中,OpenAI的估值已經翻了一倍,但新聞機構認為,該公司和微軟抄襲和盜用了自己的文章,嚴重損害了它們的商業模式。
訴訟書指出——
微軟和OpenAI輕易地攫取了記者、新聞工作者、評論員、編輯等為地方報紙作出貢獻的勞動成果——完全無視這些為地方社羣提供新聞的創作者和釋出者的付出,更遑論他們的法律權利。
而對於這些指控,OpenAI予以堅決否認。他們強調,大模型訓練中的所有工作,都符合「合理使用」法律規定。
為什麼說ChatGPT沒有「合理使用」資料
為什麼OpenAI違反了「合理使用」法?Balaji在長篇博文中,列出了詳盡的分析。
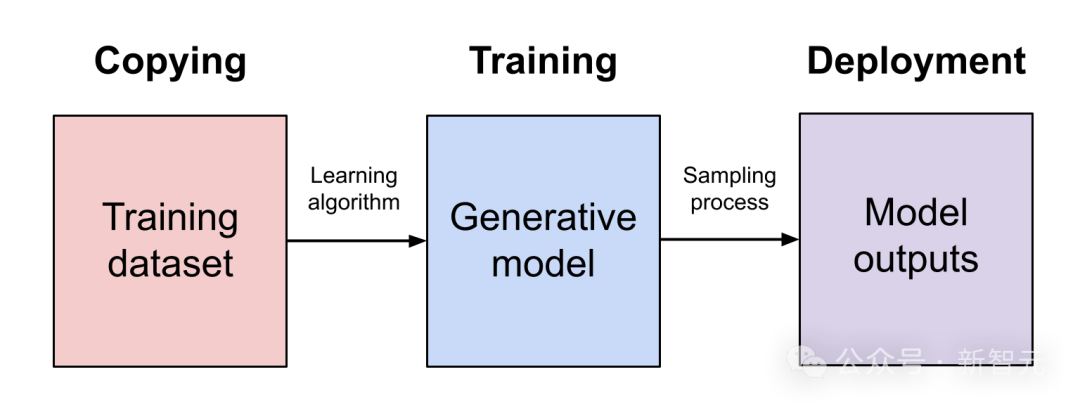
他引用了1976年《版權法》第107條中對「合理使用」的定義。
是否符合「合理使用」,應考慮的因素包括以下四條:
(1)使用的目的和性質,包括該使用是否具有商業性質或是否用於非營利教育目的;(2)受版權保護作品的性質;(3)所使用部分相對於整個受版權保護作品的數量和實質性;(4)該使用對受版權保護作品的潛在市場或價值的影響。
按(4)、(1)、(2)、(3)的順序,Balaji做了詳細論證。
因素(4):對受版權保護作品的潛在市場影響
由於ChatGPT訓練集對市場價值的影響,會因資料來源而異,而且由於其訓練集並未公開,這個問題無法直接回答。
不過,某些研究可以量化這個結果。
《生成式AI對線上知識社羣的影響》發現,在ChatGPT釋出後,Stack Overflow的訪問量下降了約12%。
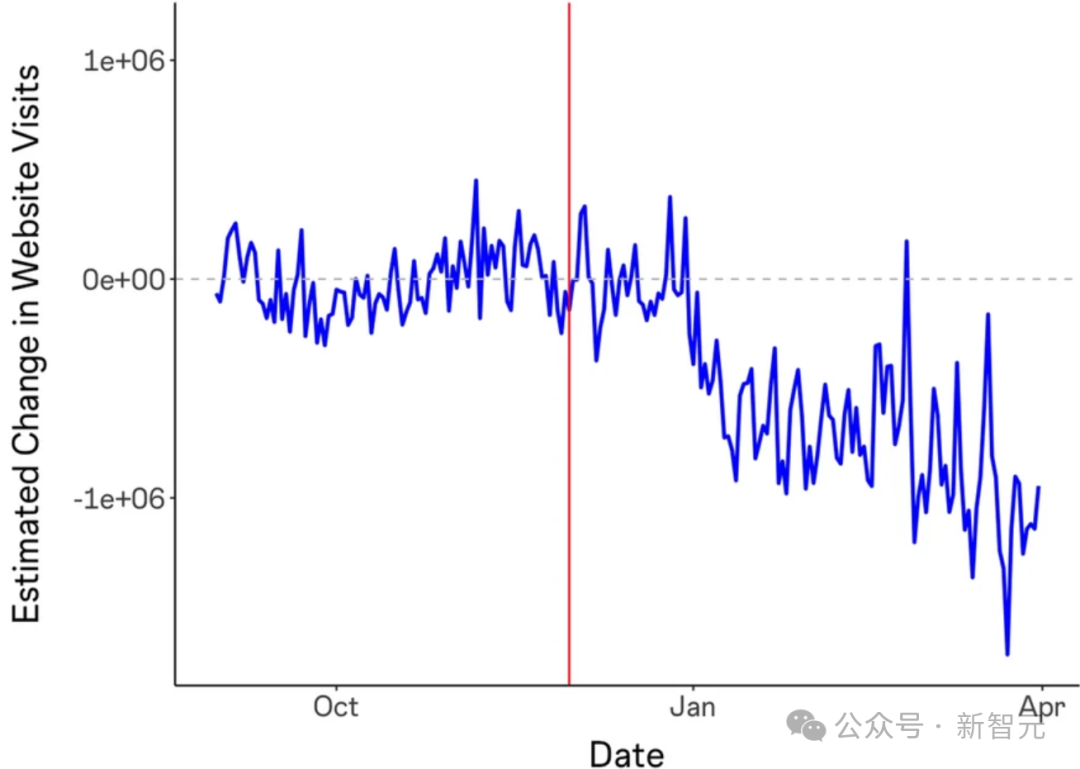
此外,ChatGPT釋出後每個主題的提問數量也有所下降。
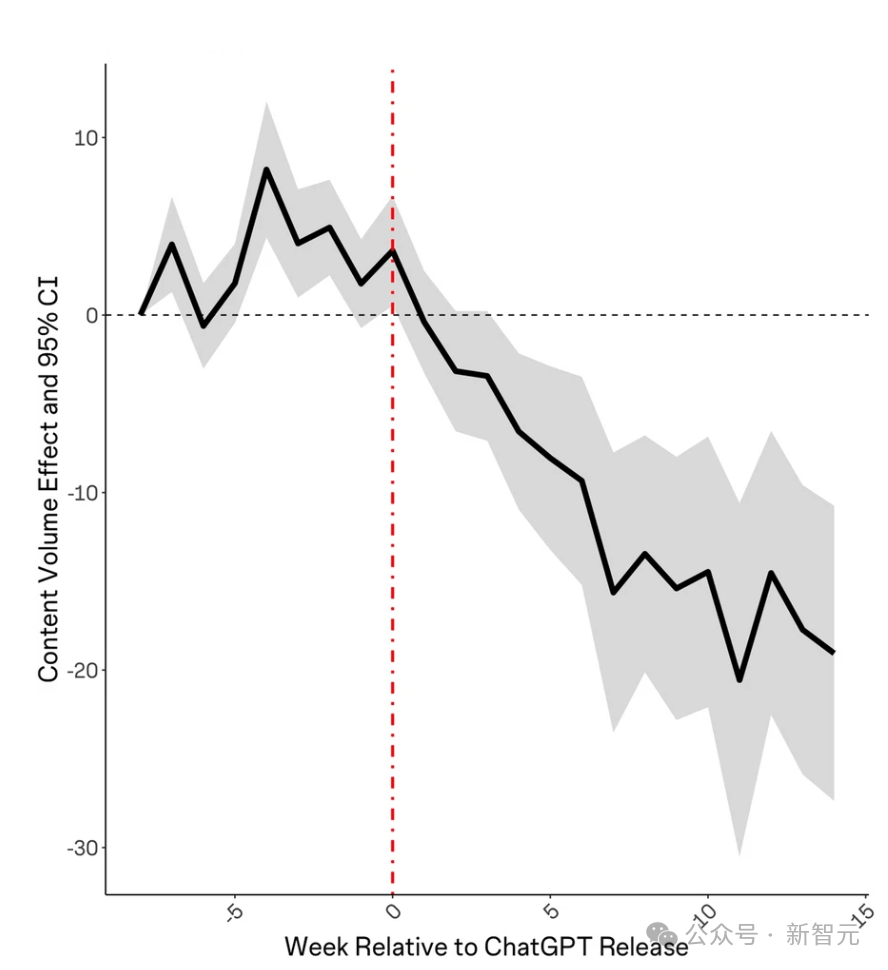
提問者的平均賬戶年齡也在ChatGPT釋出後呈上升趨勢,這表明新成員要麼沒有加入,要麼正在離開社羣。
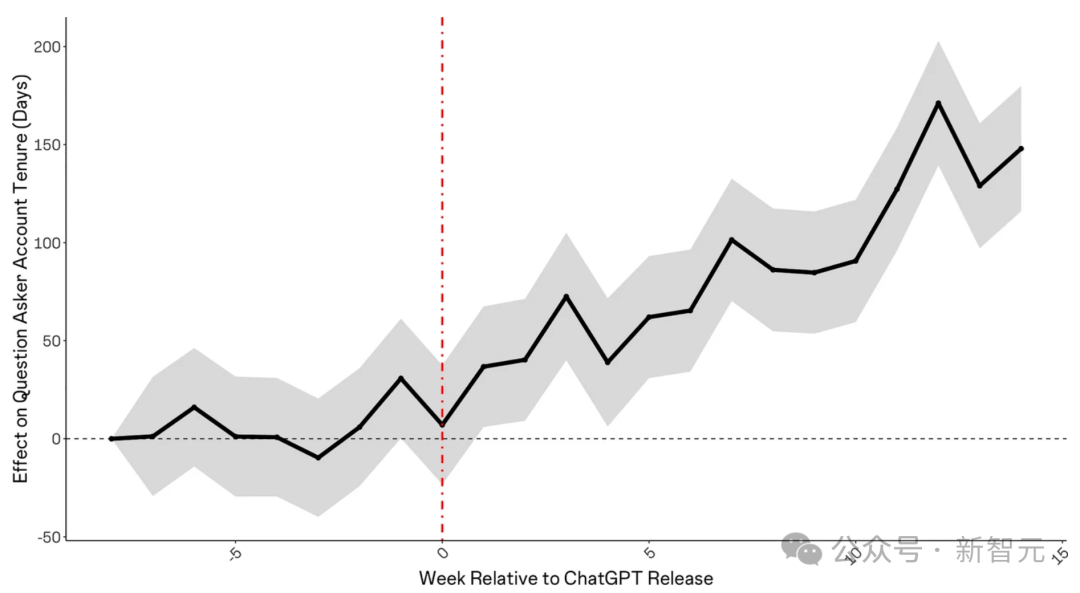
而Stack Overflow,顯然不是唯一受ChatGPT影響的網站。例如,作業幫助網站Chegg在報告ChatGPT影響其增長後,股價下跌了40%。

當然,OpenAI和谷歌這樣的模型開發商,也和Stack Overflow、Reddit、美聯社、News Corp等簽訂了資料許可協議。
但簽署了協議,資料就是「合理使用」嗎?
總之,鑑於資料許可市場的存在,在未獲得類似許可協議的情況下使用受版權保護的資料進行訓練也構成了市場利益損害,因為這剝奪了版權持有人的合法收入來源。
因素(1):使用目的和性質,是商業性質,還是教育目的
書評家可以在評論中引用某書的片段,雖然這可能會損害後者的市場價值,但仍被視為合理使用,這是因為,二者沒有替代或競爭關係。
這種替代使用和非替代使用之間的區別,源自1841年的「Folsom訴Marsh案」,這是一個確立合理使用原則的里程碑案例。

問題來了——作為一款商業產品,ChatGPT是否與用於訓練它的資料具有相似的用途?
顯然,在這個過程中,ChatGPT創造了與原始內容形成直接競爭的替代品。
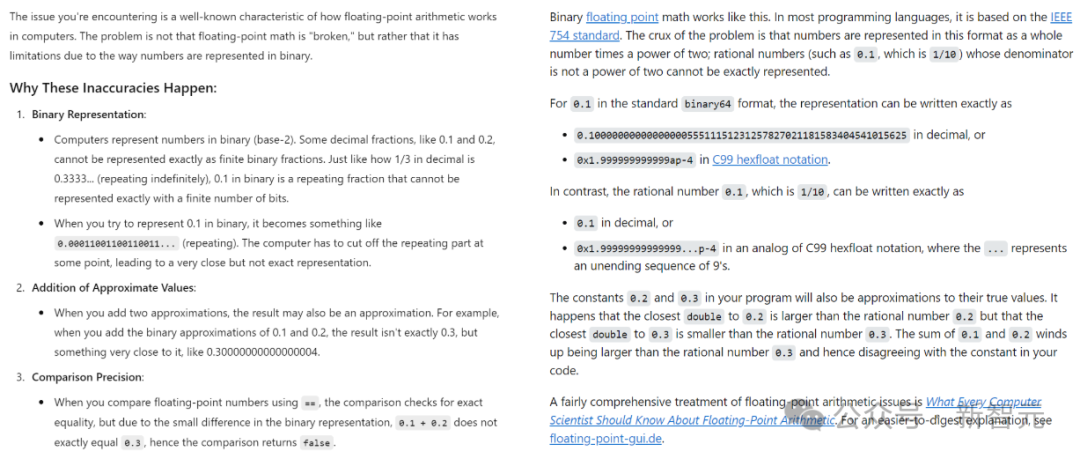
比如,如果想知道「為什麼在浮點數運算中,0.1+0. 2=0.30000000000000004?」這種程式設計問題,就可以直接向ChatGPT(左)提問,而不必再去搜尋Stack Overflow(右)。
因素(2):受版權保護作品的性質
這一因素,是各項標準中影響力最小的一個,因此不作詳細討論。
因素(3):使用部分相對於整體受保護作品的數量及實質性
考慮這一因素,可以有兩種解釋——
(1)模型的訓練輸入包含了受版權保護資料的完整副本,因此「使用量」實際上是整個受版權保護作品。這不利於「合理使用」。
(2)模型的輸出內容幾乎不會直接複製受版權保護的資料,因此「使用量」可以視為接近零。這種觀點支援「合理使用」。
哪一種更符合現實?
為此,作者採用資訊理論,對此進行了量化分析。
在資訊理論中,最基本的計量單位是位元,代表著一個是/否的二元選擇。
在一個分佈中,平均資訊量稱為熵,同樣以位元為單位(根據夏農的研究,英文文字的熵值約在每個字元0.6至1.3位元之間)。
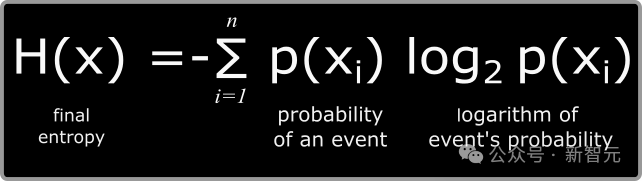
兩個分佈之間共享的資訊量稱為互資訊(MI),其計算公式為:
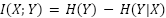
在公式中,X和Y表示隨機變數,H(X)是X的邊際熵,H(X|Y)是在已知Y的情況下X的條件熵。如果將X視為原創作品,Y視為其衍生作品,那麼互資訊I(X;Y)就表示創作Y時借鑑了多少X中的資訊。
對於因素3,重點關注的是互資訊相對於原創作品資訊量的比例,即相對互資訊(RMI),定義如下:
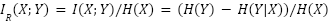
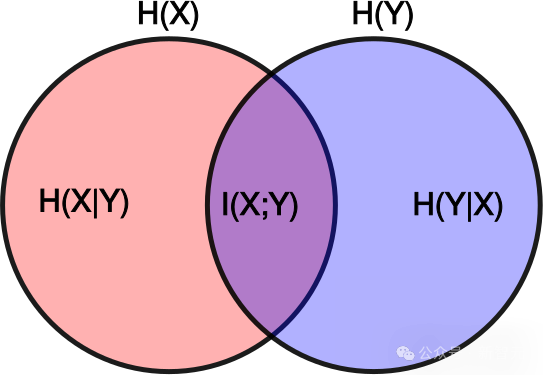
此概念可用簡單的視覺模型來理解:如果用紅色圓圈代表原創作品中的資訊,藍色圓圈代表新作品中的資訊,那麼相對互資訊就是兩個圓圈重疊部分與紅色圓圈面積的比值:
在生成式AI領域中,重點關注相對互資訊(RMI),其中X表示潛在的訓練資料集,Y表示模型生成的輸出集合,而f則代表模型的訓練過程以及從生成模型中進行取樣的過程:
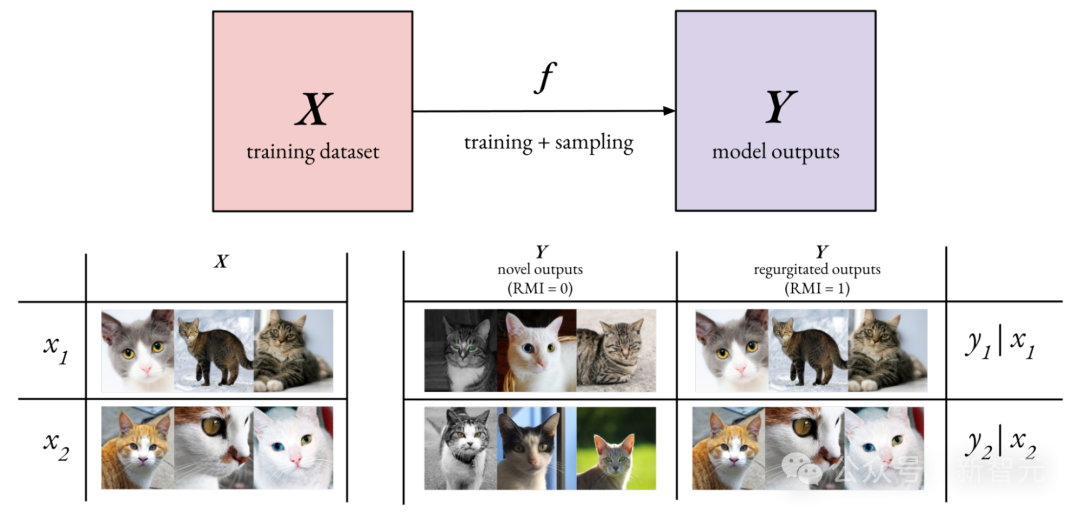
在實踐中,計算H(Y|X)——即已訓練生成模型輸出的資訊熵——相對容易。但要估算H(Y)——即在所有可能訓練資料集上的模型輸出總體資訊熵——則極其困難。
至於H(X)——訓練資料分佈的真實資訊熵——雖然計算困難但仍是可行的。
可以作出一個合理假設:H(Y) ≥ H(X)。
這個假設是有依據的,因為完美擬合訓練分佈的生成模型會呈現H(Y) = H(X)的特徵,同樣,過度擬合併且記憶訓練資料的模型也是如此。
而對於欠擬合的生成模型,可能會引入額外的噪聲,導致H(Y) > H(X)。在H(Y) ≥ H(X)的條件下,就可以為RMI確定一個下限:
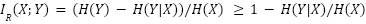
這個下限背後的基本原理是:輸出的資訊熵越低,就越可能包含來自模型訓練資料的資訊。
在極端情況下,就會導致「內容重複輸出」的問題,即模型會以確定性的方式,輸出訓練資料中的片段。
即使在非確定性的輸出中,訓練資料的資訊仍可能以某種程度被使用——這些資訊可能被分散融入到整個輸出內容中,而不是簡單的直接複製。
從理論上講,模型輸出的資訊熵並不需要低於原始資料的真實資訊熵,但在實際開發中,模型開發者往往傾向於選擇讓輸出熵更低的訓練和部署方法。
這主要是因為,熵值高的輸出在取樣過程中會包含更多隨機性,容易導致內容缺乏連貫性或產生虛假資訊,也就是「幻覺」。
如何降低資訊熵?
資料重複現象
在模型訓練過程中,讓模型多次接觸同一資料樣本是一種很常見的做法。
但如果重複次數過多,模型就會完整地記下這些資料樣本,並在輸出時簡單地重複這些內容。
舉個例子,我們先在莎士比亞作品集的部分內容上對GPT-2進行微調。然後用不同顏色來區分每個token的資訊熵值,其中紅色表示較高的隨機性,綠色表示較高的確定性。

當僅用資料樣本訓練一次時,模型對「First Citizen」(第一公民)這一提示的補全內容雖然不夠連貫,但顯示出高熵值和創新性。
然而,在重複訓練十次後,模型完全記住了《科利奧蘭納斯》劇本的開頭部分,並在接收到提示後機械地重複這些內容。
在重複訓練五次時,模型表現出一種介於簡單重複和創造性生成之間的狀態——輸出內容中既有新創作的部分,也有記憶的內容。
假設英語文字的真實熵值約為每字元0.95位元,那麼這些輸出中就有大約
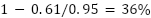
的內容是來自訓練資料集。
強化學習機制
ChatGPT產生低熵輸出的主要原因在於,它採用了強化學習進行後訓練——特別是基於人類反饋的強化學習(RLHF)。
RLHF傾向於降低模型的熵值,因為其主要目標之一是降低「幻覺」的發生率,而這種「幻覺」通常源於取樣過程中的隨機性。
理論上,一個熵值為零的模型可以完全避免「幻覺」,但這樣的模型實際上就變成了訓練資料集的簡單檢索工具,而非真正的生成模型。
下面是幾個向ChatGPT提出查詢的示例,以及對應輸出token的熵值:

根據
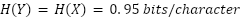
,可以估計這些輸出中約有73%到94%的內容,對應於訓練資料集中的資訊。
如果考慮RLHF的影響(導致
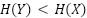
),這個估計值可能偏高,但熵值與訓練資料使用量之間的相關性依然十分明顯。
例如,即使不瞭解ChatGPT的訓練資料集,我們也會發現它講的笑話全是靠記憶,因為這些內容幾乎都是以確定性方式生成的。
這種分析方法雖然比較粗略,但它揭示了訓練資料集中的版權內容如何影響模型輸出。
但更重要的是,這種影響十分深遠。即使是對因素(3)做出更寬鬆的解釋,也難以支援「合理使用」的主張。
最終,Suchir Balaji得出結論:從這4個因素來看,它們幾乎都不支援「ChatGPT在合理使用訓練資料」。
10月23日,Balaji發出這篇部落格。
一個月後,他死於自己的公寓。
相關文章
- 26歲OpenAI舉報人疑自殺!死前揭ChatGPT訓練黑幕
- 新版Llama 3 70B反超405B!Meta開卷後訓練,谷歌馬斯克都來搶鏡
- 瓊瑤一生曾多次自殺
- 瓊瑤自殺離世,遺書內容曝光,林青霞趙麗穎等半個娛樂圈發文悼念
- 瓊瑤自殺去世!生前安排好一切,遺書直言此生無憾,最後露面曝光
- 86歲瓊瑤自殺曝光:隱居5.5億豪宅,公然做小三,曾說一生無悔!
- 瓊瑤自殺離世享年86歲,趙薇范冰冰發文悼念:謝謝您曾點亮我!
- 美國6大科技公司市值暴漲8萬億美元!ChatGPT推出兩週年,大公司更強了
- ChatGPT兩歲,OpenAI 10億使用者計劃曝光
- OpenAI遭加拿大五大媒體起訴,稱其非法抓取新聞訓練ChatGPT等AI模型