
AI界拼多多!杭州大模型DeepSeek,訓練僅花4000萬元,美國AI大佬全炸出來了
鳳凰科技 2024-12-29 01:35:15 1
延續便宜大碗的特點,DeepSeek V3釋出即開源。
還用53頁論文 ,分享訓 練細節。
更重要的是,大家第一時間在論文中發現了關鍵細節:
訓練過程,便宜又省錢!
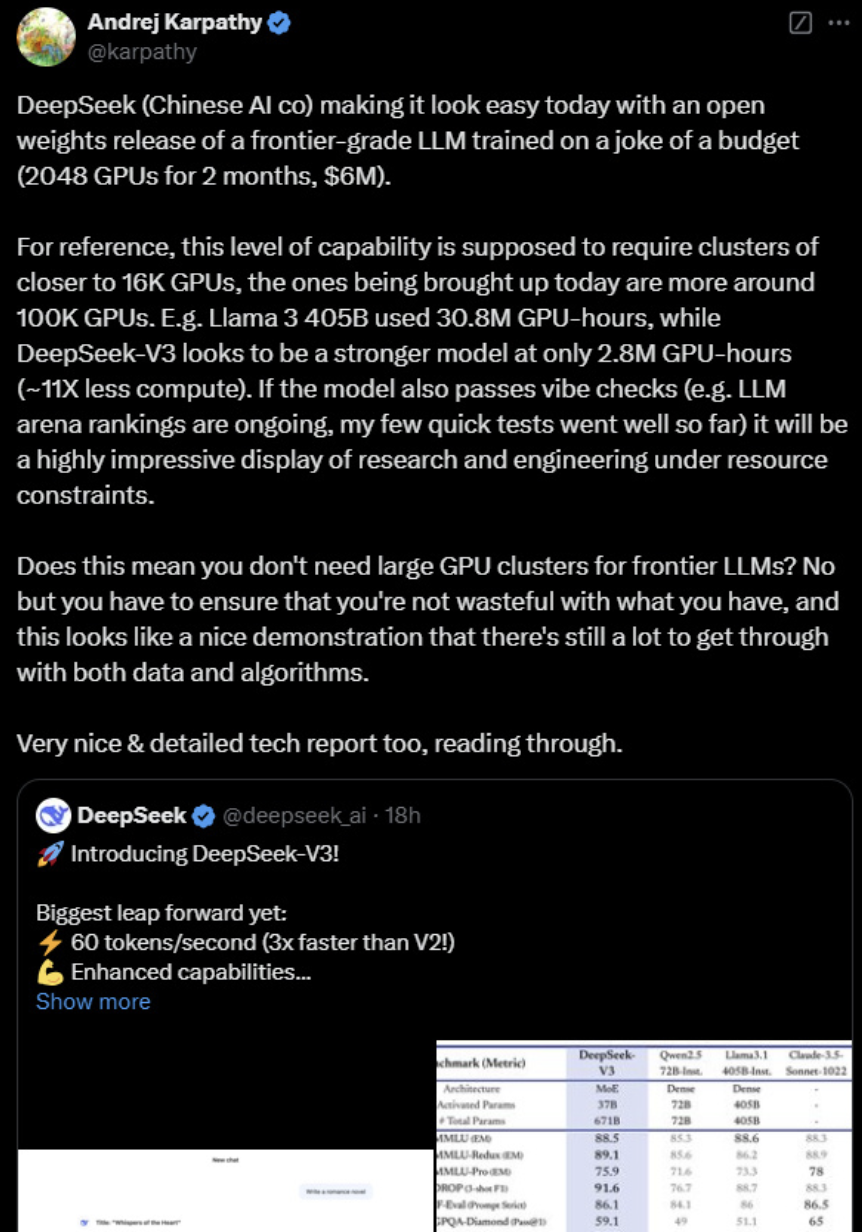
DeepSeek 用十分之一的算力,做出了和 GPT-4o 及 Claude-3.5-Sonnet 效能相當的模型!
DeepSeek V3整個訓練過程僅用了不到280萬個GPU小時。
對比參考:Llama 3 405B的訓練時長是3080萬GPU小時。
訓練671B的DeepSeek V3的成本是557.6萬美元(約合4070萬人民幣)。
而同類模型,大概需要1.5萬塊 H100,DeepSeek用了 2048 塊H800就做出來了。
海外對deepseek的讚歎和不解,遠高於國內。
OpenAI創始成員AK對此讚道:
DeepSeek V3讓在有限算力預算上進行模型預訓練這件事變得容易。
DeepSeek V3看起來比Llama 3 405B更強,訓練消耗的算力卻僅為後者的1/11。
Meta科學家田淵棟,說DeepSeek V3的訓練,看上去是“黑科技”: 這是非常偉大的工作。
Menlo Venture的投資人也感慨: “53 頁的技術論文是黃金” (53-page technical paper is GOLD)。
英偉達高階研究科學家Jim Fan,轉發OpenAI創始成員AK的推文表示: 資源限制是一件美好的事情。 在殘酷的人工智慧競爭環境中,生存本能是取得突破的主要動力。
“我關注 DeepSeek 很久了。去年他們推出了最好的開源模型之一,卓越的OSS模型給商業前沿 LLM 公司帶來了巨大壓力,迫使它們加快步伐。”
前阿里巴巴副總裁賈揚清認為:
DeepSeek 的成功是簡單的智慧和實用主義在起作用,在計算和人力有限的情況下,透過智慧研究產生最佳結果。

論文結尾,再次強調了 「以開源精神和長期主義追求普惠 AGI」。
當然“小力出奇跡”也是相對的,因為公司自身家底殷實。
幻方量化是國內唯一公開宣稱有擁有萬張英偉達A100顯示卡的企業,其算力儲備量就算是在一眾網際網路公司科技公司裡也豪不遜色。

如此厲害的大模型,不是網際網路科技巨頭研發的,國內最牛的AI巨頭(之一),竟然是炒股的?
金融領域的頭部量化:幻方量化。
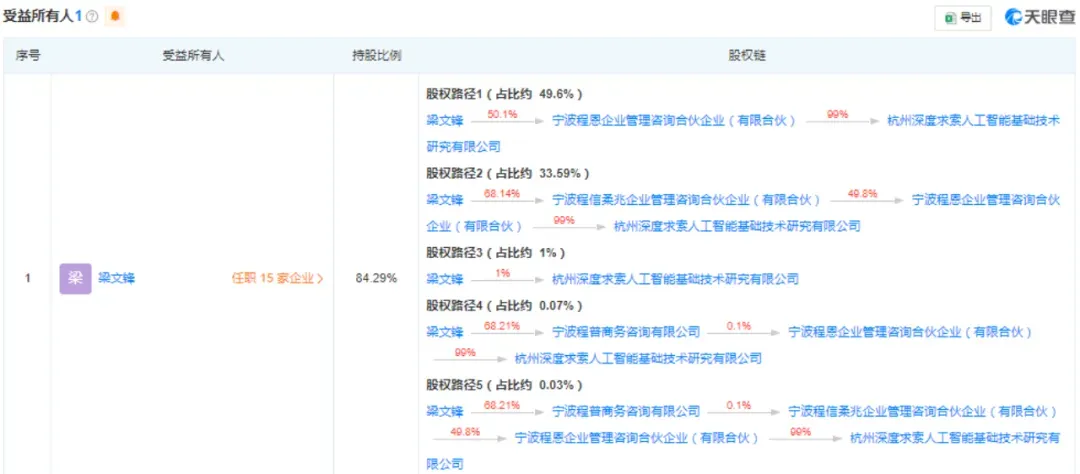
梁文鋒 是幻方量化的實際控制人,他在DeepSeek最終受益的股份比例超80%。
他本碩就讀於浙江大學,攻讀人工智慧,唸書時就篤定 「AI定會改變世界」。
畢業後,梁文鋒沒有走程式設計師的既定路線,而是下場做量化投資,成立幻方量化。幻方量化成立僅6年管理規模即曾達到千億,被稱為「量化四大天王」之一。
幻方量化也是迄今為止,業內唯一規模曾邁過千億大關的量化私募。
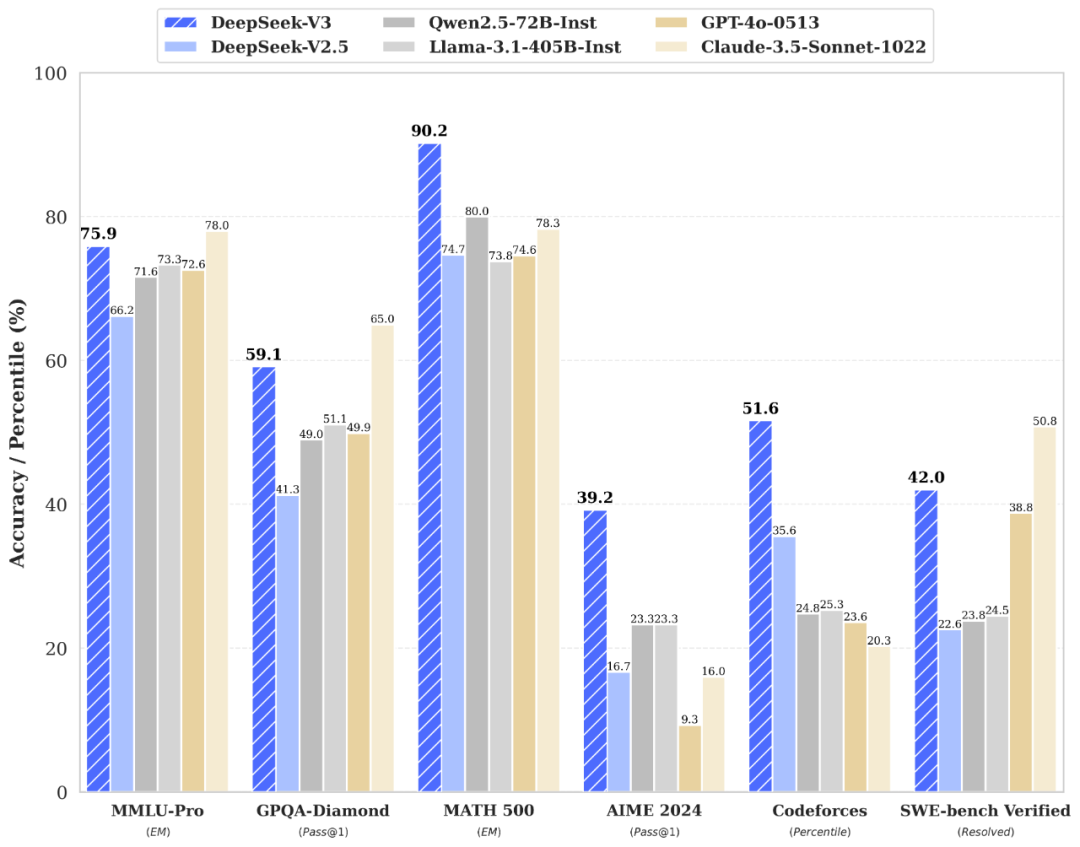
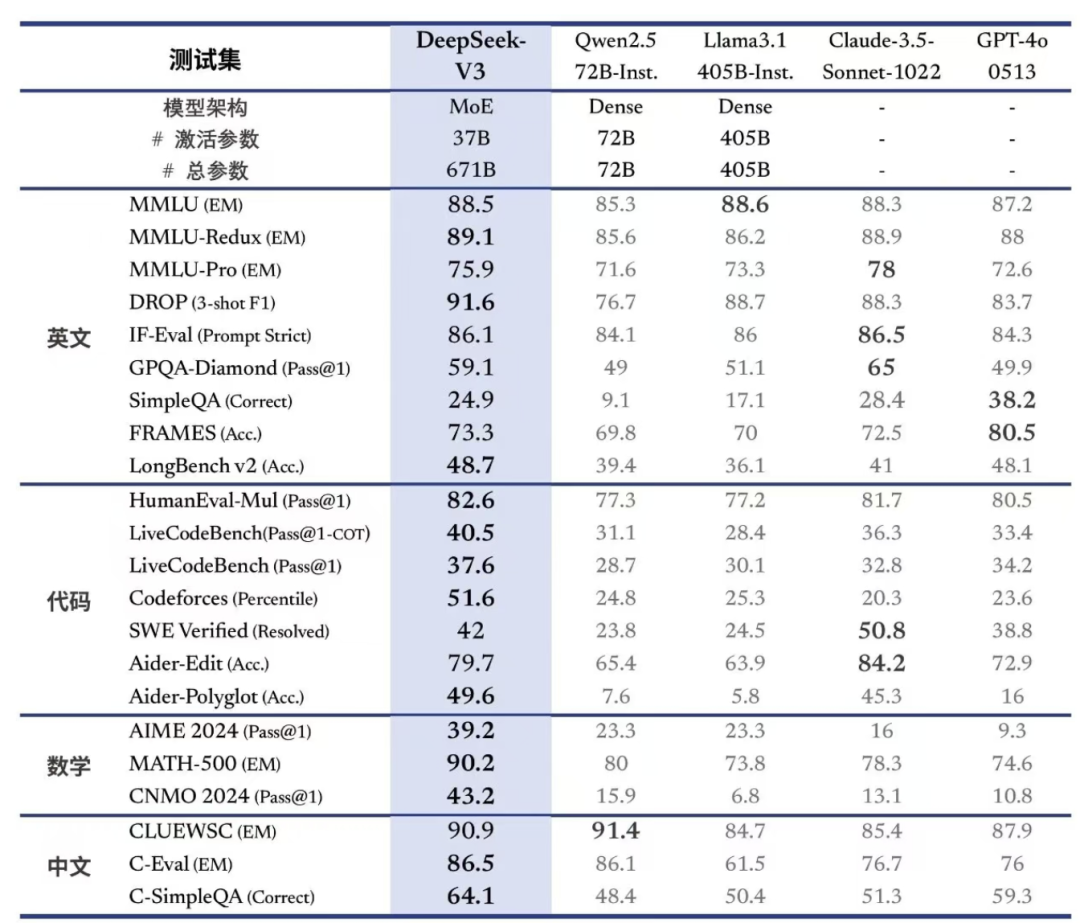
DeepSeek-V3 為自研 MoE 模型,671B 引數,啟用 37B,在 14.8T token 上進行了預訓練。
DeepSeek-V3 多項評測成績超越了 Qwen2.5-72B 和 Llama-3.1-405B 等其他開源模型,在效能上和世界頂尖模型 GPT-4o 以及 Claude-3.5-Sonnet相差無幾。
此前DeepSeek一直被冠以 “AI界拼多多”。
它開啟了中國大模型價格戰。
2024年5月,DeepSeek釋出的一款名為DeepSeek V2的開源模型,提供了史無前例的價效比:
推理成本被降到每百萬token僅 1塊錢,在當時約等於Llama3 70B的七分之一,GPT-4 Turbo的七十分之一。
隨後,位元組、騰訊、百度、阿里、kimi等AI公司跟隨降價。
現在,登入deepseek官網,即可與最新版 V3 模型對話。當前版本的 DeepSeek-V3 暫不支援多模態輸入輸出。
更新上線的同時,DeepSeek 調整了 API 服務價格——模型 API 服務定價調整為每百萬輸入 tokens 0.5 元(快取命中)/ 2 元(快取未命中),每百萬輸出 tokens 8 元。
官方還為全新模型設定長達 45 天的優惠價格體驗期:
即日起至 2025 年 2 月 8 日,DeepSeek-V3 的 API 服務價格仍然是每百萬輸入 tokens 0.1 元(快取命中)/ 1 元(快取未命中),每百萬輸出 tokens 2 元,已經註冊的老使用者和在此期間內註冊的新使用者均可享受以上優惠價格。
國內不少公司習慣於跟隨海外科技公司,參考技術做應用變現。
即使是網際網路大廠在創新方面也較為謹慎,更加重視應用層面。
DeepSeek逆向而行,選擇了一條更具挑戰的道路。它不滿足於僅僅成為跟隨者,而是從架構創新入手,提出了突破性的MLA架構,在全球AI大模型領域留下了獨特的中國印記。
正如DeepSeek創始人梁文峰所說:「中國也要逐步成為貢獻者,而不是一直搭便車。」
相關文章
- 廣東江門一門店新會陳皮賣到12.8萬元/斤?回應:46年存貨僅4斤,收藏價值遠超實用價值
- WTT引發眾怒,考驗劉國樑智慧的時候來了
- 對標3萬元的Vision Pro!vivo MR原型機明年上線:部分體驗已超越蘋果
- 它讓M4 Mac mini立起來了,1000元內搞定2TB儲存升級
- 人氣碾壓周杰倫的“媽屆”頂流,憑什麼敢賣萬元演唱會票?
- 美國同學曝劉亦菲班級合照:12歲是校花坐C位,同學來自五湖四海
- NewCo弱爆了,美國Biotech開始流行“專利權”融資
- AI界拼多多!杭州大模型DeepSeek,訓練僅花4000萬元,美國AI大佬全炸出來了
- 美國搞晶片,兩頭不討好?
- 鄭爽曬美國過節照,吃水果沙拉沒有煙火氣,又在懷念國內生活了