
一條晶片“新”賽道,悄然崛起
鳳凰數碼 2024-12-01 01:42:34 2
GPU超越了CPU。這也意味著,在計算領域,專用計算打敗了通用計算。然而,儘管專用計算的優勢日益明顯,仍有一部分初創公司堅持走通用計算的道路,力圖透過創新突破當前架構的瓶頸,重新定義處理器的未來。在這個日益分化的計算時代,通用計算是否依然有機會與專用計算一較高下?一些雄心勃勃的初創公司正在投入巨資和大量的研發力量,試圖透過開發全新的通用處理器架構來挑戰現有格局。
通用處理器的黃金時代
回顧過去,通用處理器(CPU)曾在計算領域主宰了數十年。在70年代到90年代,CPU曾是幾乎所有計算任務的主力。
1971年,英特爾釋出了4004處理器,這是世界上第一款商用微處理器,標誌著計算機技術的一個新紀元。隨後,英特爾在1974年釋出的 8080 處理器,以及其後續的 x86 架構,為個人計算機(PC)提供了強大的處理能力。
1981年,IBM個人計算機(IBM PC)的釋出,將基於 x86 架構的通用處理器推向了全球市場。
進入1990年代,隨著網際網路的崛起和計算需求的多樣化,Intel 和 AMD 等公司繼續推動 x86 架構 的發展,通用處理器的市場份額不斷擴大。英特爾的 Pentium 處理器系列(1993年推出)標誌著高效能運算的到來。此外,90年代的企業級伺服器和資料中心也開始大量採用基於 x86 架構的通用處理器。這一時期,通用處理器不僅在桌面和辦公應用中佔據主導地位,也逐漸成為伺服器、資料中心以及高效能運算(HPC)領域的主力。
從 2000年代後期開始,隨著 GPU 和專用加速器(如 TPU、FPGA)的崛起,計算界的天平開始發生傾斜。
進入AI時代,計算需求呈現出爆炸式增長。深度學習等AI演算法對計算資源的需求遠遠超過了傳統應用。GPU憑藉其高度並行的架構,在訓練和推理大規模神經網路方面表現出色,成為了AI訓練的“標配”。這一時期,GPU在圖形處理、科學計算以及機器學習等領域的表現,逐漸超越了傳統的CPU。與此同時,各種專用積體電路(ASIC)也在不斷湧現,針對特定AI演算法進行最佳化,進一步提升了計算效率。
儘管GPU和ASIC在特定領域的優勢非常明顯,但它們也有不可忽視的缺點。首先,GPU 和 ASIC 是專為某些特定任務設計的,缺乏通用性和靈活性。如果面對複雜的計算任務或需要多種計算能力的應用,GPU 和 ASIC 就顯得不那麼高效。此外,GPU 和 ASIC 的開發和生產成本較高,且其硬體架構通常與現有的計算環境不相容,這使得大量企業在進行硬體更新時面臨著較高的技術門檻和經濟成本。
正是這些缺口,令一些初創公司找到了彎道超車的著力點。在AI時代的快速洗禮下,資料中心的挑戰和痛點愈發凸顯:居高不下的功耗、較低的伺服器利用率以及難以跟上需求的處理器效能。
初創公司Tachyum:
各種PU大亂燉,能成嗎?
初創公司Tachyum提出了一種大膽的願景:將超大規模資料中心轉變為真正的通用計算中心。
他們是如何做的呢?Tachyum推出了一種新型通用處理器,將CPU、GPGPU 和 TPU的功能統一到單個單片裝置中,無需昂貴且耗電的加速器,而是透過使用與軟體可組合性和伺服器資源的動態重新分配相一致的簡單同質軟體模型來最大限度地提高利用率,以此來滿足雲和 HPC/AI 工作負載的高需求。該架構速度更快、功耗降低10倍、成本僅為競爭產品的 1/3。
下圖是早期(2022年)Tachyum公司對Prodigy架構的構思,它整合了128個自定義的 64 位 CPU 核心,執行頻率最高可達 5.7 GHz,有十六個DDR5記憶體控制器,支援最高DDR5-7200,和64條PCIe 5.0 通道。CPU、記憶體控制器和I/O透過Tachyum自定義設計的10 Tbps非阻塞全網狀網際網路絡連線在一起。Prodigy提供了一種尖端的“系統晶片”設計,平衡了高效能的CPU 核心、記憶體、I/O和互聯子系統。
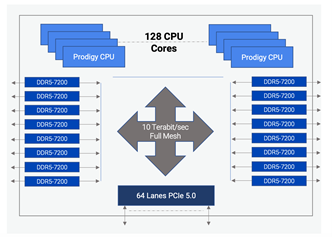
Prodigy裝置架構圖(來源:Tachyum Prodigy架構白皮書,2022)
Prodigy採用獨特的“半晶片(half-chip)”設計,使得這款128核的裝置可以作為兩個獨立的64核裝置工作,每個裝置配備8個DDR5記憶體控制器、32條PCIe 5.0通道、獨立的電源平面,並具備單獨啟動的能力。這帶來了多個好處。首先,從客戶的角度來看,兩個功能裝置可以部署在一個單一封裝中,節省成本、板空間和功耗,併為系統和板設計者提供靈活性。從運營的角度來看,這種架構為Tachyum提供了更高的64核晶片良率。如果“北半部分”出現問題,可以將晶片旋轉180度,“南半部分”將成為正常工作的 64 核裝置。
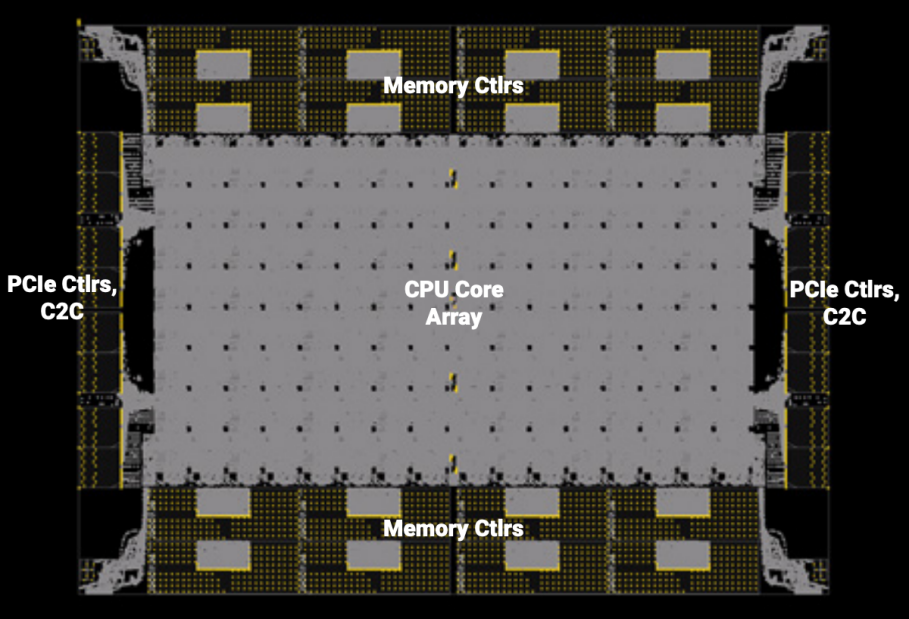
Prodigy裝置佈局主要功能模組(來源:Tachyum Prodigy架構白皮書,2022)
Tachyum在白皮書中指出,處理器效能停滯不前的根本原因是處理器矽片上的線路延遲增加。隨著矽片工藝的縮小,電晶體的速度加快,但線路的速度卻減慢了,我們現在正處於效能受到線路延遲限制的階段。由於線路的電阻率是線路橫截面積的函式,因此電阻率會隨著工藝縮小的平方而增加,工藝幾何尺寸每減小10 倍會導致電阻率增加100倍,這與線路延遲成正比。業界的方法是從鋁互連轉換為銅互連並使用低 K 電介質,這確實有所幫助,但線路延遲仍然是限制處理器效能一代一代提升的主要因素。
為了解決過去二十年中由於工藝縮小導致電晶體加速但導線變慢,從而導致處理器效能停滯的問題,並且最大化效能、可擴充套件性和靈活性、最小化總擁有成本(TCO),Tachyum 為其Prodigy處理器開發了新的指令集架構(ISA)。該架構結合了RISC(精簡指令集和CISC(複雜指令集)的特點,但沒有包含許多 CISC 處理器中常見的複雜和/或變長的低效指令。所有指令的寬度為 32 位或 64 位,其中一些指令還包括記憶體訪問,以最佳化效能。Prodigy ISA 包含大量的向量和矩陣指令,這些指令最佳化了向量和矩陣運算的效能和效率。新ISA透過將執行單元感知(execution unit awareness)引入指令集架構,從而使Prodigy微架構和 Prodigy 編譯器能夠協同工作,避免了執行單元之間消耗大量功耗的資料傳輸,並減少了晶片內延遲。
最初Prodigy系列處理器包括128核、64核和32核的型號,而在最新的產品披露中,Prodigy對其產品構想進行了全面的升級:Prodigy SKU家族包含192核、96核、48核多個型號,適用於從超算到大規模AI、超大規模資料中心和邊緣伺服器等各類應用。TDP(熱設計功耗)範圍從48核入門級的150 W,到頂端型號的950W。
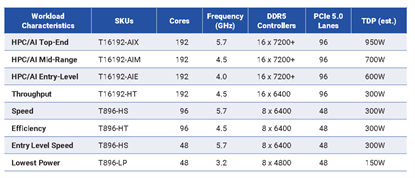
Prodigy各型號的規格(來源:Tachyum)
Prodigy的競爭賣點在哪裡呢?據該公司白皮書的分析,其統一架構通用處理器直接與CPU和GPGPU競爭。
下圖顯示了Prodigy、Nvidia H200 GPU和 ntel Xeon 8380 CPU之間的正面對比,展示了 Prodigy 通用處理器如何與CPU和GPU架構直接競爭。比較結果表明,與 H200 GPU 和 Intel Xeon 8380 CPU 相比,Prodigy 在多個工作負載和資料型別下提供了更高的效能和每瓦效能。
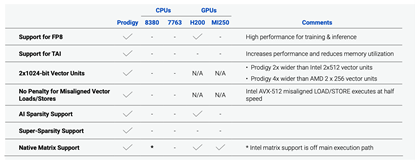
具體而言,Prodigy比 Intel Xeon 8380擁有3倍的CPU核心數,主頻是8380的2.5倍,記憶體頻寬約為8380的20倍。Prodigy的Specrate 2017整數得分是8380的4倍,而 Prodigy 的FP64峰值效能是8380的30倍。
與Nvidia H200比較,Prodigy的16條DDR5-7200通道和頻寬放大技術提供了約 2TB/sec 的頻寬,同時保留了支援大記憶體和擴充套件性的靈活性,DIMM 可提供較大的記憶體支援。H200 使用 HBM3 提供 3 TB/sec 的頻寬,但將記憶體足跡限制為 80GB 的固定記憶體。Prodigy 和 H200 都支援從 FP64 到 FP8 的多種資料型別,並且都支援 4:2 稀疏性。但與 H200 不同,Prodigy 除了支援 4:2 稀疏性外,還支援 8:3 超稀疏性,提供了更高的效能,僅有輕微的精度折衷。此外,Prodigy 擁有更大的快取,減少了對 DRAM 頻寬的需求。Prodigy 還支援 TAI(Tachyum AI),一種新的資料型別,能提供更大的效能提升。
為了全面瞭解 Prodigy的能力,一個1.6萬億引數的Switch Transformer 需要 52 個 NVIDIA H200 80GB GPU(每個成本為 41,789 美元)和7個Supermicro GPU伺服器(每個成本為 25,000 美元),總成本為 2,348,028 美元。而該公司聲稱,一個配備 2TB DDR5 DRAM的Prodigy單個插槽系統可就以容納和執行如此大的模型,成本僅為23,000美元,這僅是英偉達方案成本的1/100。如果真如此,這將是一個顛覆性的通用處理器。
理論上都很美好,但是目前Tachyum公司最大的問題是,尚沒有實際的產品出來。Prodigy的推出時間一再延遲,今年推明年。Prodigy通用處理器最初計劃於2019年推出,並於2020年上市。然而它不斷推遲,推遲到2021年,然後是2022年,然後是2023年。最新的訊息是,據該公司稱,採用5nm工藝的Prodigy處理器將於明年流片和量產。一個小插曲是,此前該公司還起訴了EDA公司Cadence,說他們的設計未能滿足效能目標。
據報道,Tachyum已收到一份大型採購訂單,用於構建一個大型系統。據Tom's Hardware報道,Tachyum還計劃於 2026 年釋出 Prodigy 2,這是一款使用 PCIe 6.0 和 CXL 的 3nm 處理器,以及高頻寬記憶體 (HBM) 3 RAM。
我們也希望明年真的能見到這款強大的通用處理器。
Ubitium:通用RISC-V微處理器
德國初創公司Ubitium,這家公司成立於2024年。創始人的履歷頗豐:董事長/聯合創始人Peter W Weber層就職於英特爾、德州儀器、Siliconix等;執行長/聯合創始人Hyun Shin Cho;技術長/聯合創始人Martin Vorbach在大學期間創辦了自己的第一家微處理器公司。他創辦了可重構處理器(FPGA)領域的領軍企業 PACT XPP Technologies。PACT 的技術已授權給所有美國主要半導體公司,馬丁名下擁有200多項專利。
Ubitium旨在透過引入完全與工作負載無關的通用處理器架構從根本上改變計算格局。技術長Martin Vorbach花了15年時間開發這一通用處理器架構。Ubitium的通用處理器架構代表了計算行業的一次重大創新,它挑戰了現有的處理器設計正規化。
通用處理器陣列(來源:Ubitium)
傳統的微處理器往往需要為不同的計算任務,如圖形處理、人工智慧計算等,設計專門的硬體核心。而Ubitium希望透過同質、與工作負載無關的微處理架構,用單一、多功能的晶片取代傳統處理器(CPU、NPU、GPU、DSP 和 FPGA)來處理所有工作負載,該架構基於開源指令集 RISC-V,旨在透過統一的設計,不僅使處理器尺寸更小、能效更高,而且大幅降低成本,使其能夠適應各種應用場景。
Ubitium的設計靈感源於當前計算機體系結構面臨的瓶頸,特別是在硬體資源的高效利用 方面。當前許多處理器架構面臨著不必要的“瑣碎管理”任務——這些任務佔用了大量硬體資源卻並未直接提高效能。此外,許多高效計算技術,如同步多執行緒,往往需要額外的硬體開銷來支援,這就導致了更高的能耗和複雜性。
過去數十年來,晶片技術的進步主要圍繞尺寸展開,電晶體變得越來越小,因此透過整合更多電晶體,微處理器的功能也變得更強大。然而,設計並沒有發生根本性改變。Ubitium透過重新設計處理器的內部結構,消除了這些不必要的開銷,從而提高了效能。除了架構創新外,Ubitium還計劃推出多個晶片型號,涵蓋從小型裝置到大型計算系統的不同需求。這些晶片的陣列大小可以不同,但它們都基於相同的架構和軟體平臺。
目前,該公司擁有 18 項基於 FPGA 模擬的原型技術專利,並正在開發一系列晶片,這些晶片的陣列大小各不相同,但共享相同的底層通用架構和軟體堆疊。Ubitium所開發的通用晶片目標市場是邊緣或嵌入式裝置,幫助企業將部署成本降低100倍。不過,該公司強調,該架構具有高度可擴充套件性,未來也可用於資料中心。
雖然Ubitium的產品聽起來像是FPGA,比如都強調硬體靈活性和可重用性,但它並不是傳統意義上的FPGA。相比FPGA,Ubitium的處理器並沒有依賴於“硬體模擬”或“動態硬體配置”的方法,而是透過統一的架構和核心資源來實現不同功能。
2024年11月21日,Ubitium獲得了370萬美元種子資金。這筆投資將用於開發首批原型併為客戶準備初始開發套件,首批晶片計劃於2026年推出。不過,在短短兩年內推出一個旨在“徹底改變”行業的架構至少可以說是具有挑戰性的。目前的370萬美元幾乎可以肯定不足以讓 Ubitium的“突破性”晶片起步。通常,晶片進入流片階段需要花費數億美元。
前路挑戰不可忽視
無論是 Tachyum 還是 Ubitium,它們選擇開發通用處理器的原因,都來自於計算需求的複雜性和多樣化。傳統的計算架構,如 CPU、GPU 和 FPGA,雖然各自在特定領域中表現突出,但它們的組合和協同工作往往帶來額外的成本和複雜性。尤其是在 AI、大資料和高效能運算(HPC)日益普及的背景下,資料中心和雲端計算需要一種更高效、更靈活、更具成本優勢的解決方案。
但初創公司來做通用處理器還是會面臨很大的挑戰:
技術實現:要在同一個晶片上處理多種計算任務(如圖形處理、AI 推理、高效能運算等),需要精心設計架構,確保每種任務的計算能力都得到充分發揮而不互相干擾。Tachyum提出的架構仍處於早期階段,並且已經經歷了多次延期。產品是否能按計劃交付,以及它是否能在競爭激烈的市場中脫穎而出,仍然是一個巨大的不確定性。
市場接受度:儘管他們的晶片可能在效能上具有優勢,但市場對新架構的接受度仍然是個問題。尤其是在傳統的 CPU 和 GPU 仍佔據主流地位的情況下,新型的通用處理器是否能夠與 NVIDIA、Intel 等成熟廠商的產品競爭並獲得廣泛採用,仍有待觀察。
成本與規模化:即便後進者都宣稱其晶片在成本和功耗優勢顯著,但要實現大規模生產並降低成本,需要鉅額的研發和生產投資。處理器的製造和流片成本通常非常昂貴,因此資金的穩定和籌措將是其成功的關鍵因素。
Tachyum和Ubitium都在試圖解決計算領域的一個重要問題:如何整合多種處理功能,提供更靈活、更高效的解決方案。儘管兩者的技術願景非常吸引人,但在實現過程中面臨的技術挑戰、市場接受度以及資金問題都不容忽視。要想在競爭激烈的半導體市場中脫穎而出,除了技術突破,還需要強有力的資金支援和客戶認可。
小結
強如英特爾和AMD,在AI的浪潮中,都有點招架不住,初創公司能否掀起浪花?在這個風雲變幻的時代,通用處理器能否重奪王座呢?結果尚未知。
但可以明見的是,這條晶片“新”賽道,已經悄然崛起。