
英偉達投資了一家晶片“競爭對手”
鳳凰科技 2024-11-24 01:35:32 1
Enfabrica Corp.,一家備受矚目的初創公司,正在AI領域掀起波瀾。去年9月,該公司在B輪融資中籌集了1.25億美元,並吸引了AI巨頭英偉達的投資,這算是英偉達的一個競爭對手,因為這家初創公司研發的AI網路晶片被業界認為有望對英偉達旗下的Mellanox解決方案構成挑戰。而就在本月,Enfabrica再次完成C輪融資,獲得了包括Arm、思科、三星等巨頭的1.15億美元的資金支援。那麼,是什麼讓Enfabrica脫穎而出,吸引瞭如此多行業巨頭的持續青睞?
Enfabrica是誰?
Enfabrica這家初創公司成立於2020年,由 Sutter Hill Ventures 資助,由執行長Rochan Sankar、首席開發官 Shrijeet Mukherjee以及其他工程師創立。該公司創立之初的基本理念是資料中心的網路結構必須改變,因為底層計算正規化正在發生變化:更加並行、加速、異構和資料移動密集。

圖源:Enfabrica
直到 2023 年 3 月,該公司才開始被行業知曉。Enfabrica也被The information評為是2024年最有前途的50家初創公司。
不過成立僅4年,該公司卻獲得了一眾資本的認可:
2023年9月,Enfabrica宣佈融資1.25億美元,B 輪融資由 Atreides Management 領投,現有投資者 Sutter Hill Ventures 參投,新支持者包括 IAG Capital Partners、Liberty Global Ventures、Nvidia Corp.、Valor Equity Partners 和 Alumni Ventures。
2024年11月19日,該公司宣佈籌集了1.15億美元可觀的新現金注入,其C輪融資由 Spark Capital 領投,加入此輪融資的新投資者包括 Arm、Cisco Investments、Maverick Silicon、Samsung Catalyst Fund 和 VentureTech Alliance。去年參與 B 輪融資的現有投資者 Atreides Management、Sutter Hill Ventures、Alumni Ventures、IAG Capital 和 Liberty Global Ventures 也參與了此次融資。
隨著OpenAI的ChatGPT等大語言模型的興起,對生成式AI應用以及現在的AI代理產生了巨大的需求,這家初創公司適時推出了其AI網路互連晶片——ACF-S(Accelerated Compute Fabric-Switch,加速計算結構交換機)。ACF解決方案是從頭開始發明和開發的,旨在解決GPU網路痛點以及記憶體和儲存擴充套件問題等加速計算的擴充套件挑戰。包括英偉達在內的知名投資機構對Enfabrica的大力支援,進一步證明了其技術的商業可行性和潛在價值。
網路連線,需要改變了
在現代AI伺服器和資料中心中,存在多種連線技術,可能很多人會有所迷糊,在此作簡單科普。通常我們所說的PCIe、英偉達的NVLink、AMD的Fabric這些主要是用於伺服器與伺服器之間的縱向連線。而網路技術則是指用於多個伺服器橫向連線,例如AI訓練叢集中的多節點通訊。
AI訓練過程由頻繁的計算和通訊階段交替組成,其中下一階段的計算需要等待通訊階段在所有GPU之間完成後才能啟動。通訊階段的尾部延遲(tail latency,即最後一條訊息到達的時間)成為整個系統效能的關鍵指標,因為它決定了所有GPU是否能同步進入下一階段。在這一過程中,網路的重要性愈發凸顯,網路通訊需要能夠傳輸更多的資料。若網路效能不足,這些高成本的計算叢集將無法被充分利用。而且,連線這些計算資源的網路必須具備極高的效率和成本效益。
在高效能運算(HPC)網路中,Infiniband、OmniPath、Slingshot是幾個橫向連線技術方案。
其中Infiniband主要由NVIDIA(透過其Mellanox子公司)主導,是HPC領域最成熟的網路技術之一。它以極低的延遲和高頻寬著稱,支援遠端直接記憶體訪問(RDMA),廣泛應用於超級計算和AI訓練。該技術成本較高,部署和維護複雜性較高。目前,Nvidia 是 InfiniBand 晶片的最大賣家。例如,英偉達的ConnectX-8 InfiniBand SuperNIC支援高達800Gb/s的InfiniBand和乙太網網路連線,能夠執行數十萬臺GPU。

英偉達的ConnectX-8 InfiniBand SuperNIC
(圖源:英偉達)
OmniPath是由英特爾推出的一種高效能網路技術,旨在與Infiniband競爭,雖然英特爾於2019年停止直接開發,但Cornelis Networks接管了該技術,繼續發展。相比Infiniband,OmniPath的硬體和部署成本更低,適合中型HPC叢集。但OmniPath的市場份額有限,生態系統不如Infiniband成熟,技術更新速度較慢。
Slingshot是由Hewlett Packard Enterprise(HPE)旗下的Cray開發的高效能網路技術。其特色在於與乙太網的相容性,適合混合HPC和企業工作負載的場景。不過,Slingshot尚未在市場中被大規模應用,市場接受度和應用案例還有待觀察。
不過與HPC網路相比較,AI對網路需求提出了更高的要求,已從最初的高效能運算要求轉向構建可在加速計算叢集之間提供一致、可靠、高頻寬通訊的系統,這些叢集現在有 10,000 個節點或更大,並且需要以類似雲的服務的形式提供。
為了打破InfiniBand的壟斷,乙太網正逐漸成為有力競爭者。乙太網雖起源於通用網路技術,但其廣泛的生態系統、低成本和逐步增強的效能,使其在HPC和AI橫向連線技術中嶄露頭角。乙太網的優勢在於生態成熟和成本效益,但在延遲和專用功能上仍需努力。因而去年,超級乙太網聯盟(UEC)成立,該聯盟的宗旨是“新的時代需要新的網路”,UEC對新網路的定義是:效能堪比超級計算互連、像乙太網一樣無處不在且經濟高效、與雲資料中心一樣可擴充套件。UEC的創始成員包括AMD、Arista Networks、Broadcom、思科系統、Atos 的 Eviden 分拆公司、惠普企業、英特爾、Meta Platforms 和微軟。值得一提的是,後來英偉達也加入了這一聯盟。

來源:超級乙太網聯盟(UEC)
所有這些網路技術往往依賴於專用的網路介面卡(NIC)和交換機。當前,AI伺服器的網路元件如NICs、PCIe交換機和Rail Switches,大都像“煙囪式”(stovepipes)結構一樣單獨存在(如下圖所示),彼此之間缺乏統一協調,網路頻寬不足,缺乏可靠的容錯機制,難以應對AI訓練和推理過程中龐大的資料流量。

圖源:Enfabrica
這樣的結構特點還帶來了諸多痛點:如在GPU之間傳輸資料時容易產生擁堵,資料在網路中需要經過多個裝置跳轉,增加了延遲;網路負載分佈不均,可能導致“入匯擁塞”(incast),即大量資料同時到達某一點時引發的瓶頸;此外,碎片化和低效率的網路設計導致AI叢集的總成本(TCO)顯著增加,因為存在GPU和計算資源閒置的情況,造成資源浪費與頻寬利用率低,GPU間的鏈路如果發生故障,會導致整個任務停滯,影響系統的可靠性和穩定性。
行業變革日新月異,現在GPU已經取代CPU成為AI資料中心的核心處理資源,GPU和加速器計算基礎設施的資本支出在全球所有頂級雲提供商中佔據傳統計算支出的主導地位——這一切都歸功於生成式 AI 的市場潛力。但值得注意的是,目前部署在這些系統中的網路晶片,包括連線加速計算的PCIe交換機、NIC網路介面控制器和機架頂交換機,依然是為傳統x86計算架構時代設計的產品。這些裝置上 I/O 頻寬的滯後已經成為AI擴充套件的瓶頸。
網路晶片,也需要與時俱進了。本文我們所描述的Enfabrica公司,他們開發的ACF-S技術有望在這一領域佔據一席之地。
取代多種網路晶片,
ACF-S晶片要“革互連的命”
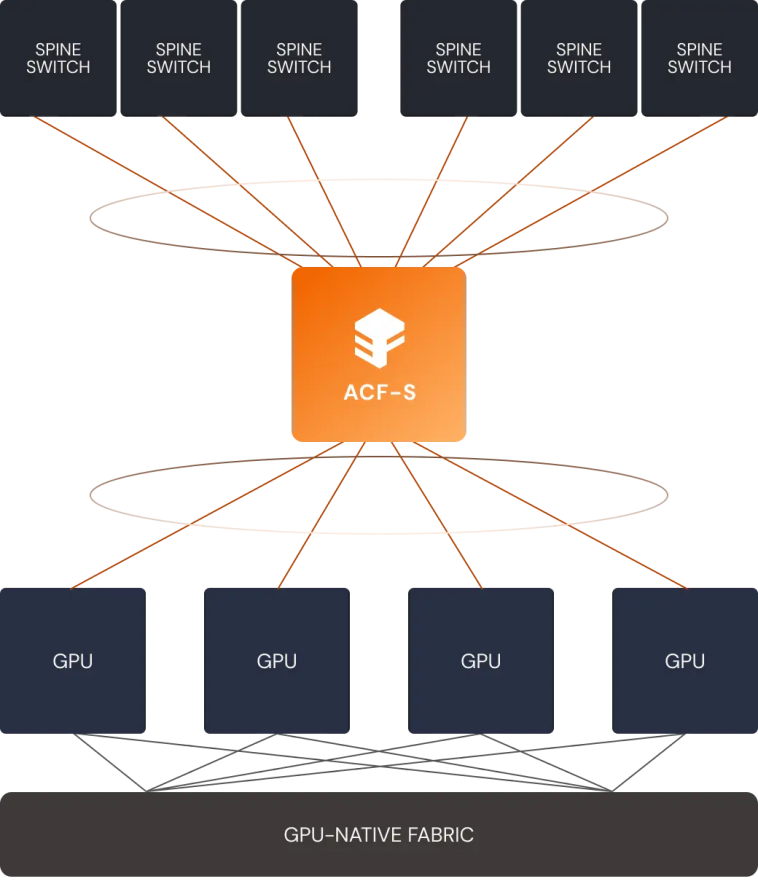
Enfabrica的ACF-S是一種伺服器結構晶片,它不使用行業標準的PCIe交換機和具有RDMA 的乙太網網路介面卡 (NIC),而是將CXL/PCIe交換功能和RNIC(遠端網路介面卡)功能整合到單一裝置中,也就是不再需要PCIe、NIC(網路介面控制器)或獨立的CPU連線DRAM,而且這種方法消除了對CXL高階功能的依賴。這種架構和思路與超級乙太網(UEC)白皮書所倡導的所有方面都需要加速器、NIC 和交換機結構之間的協調不謀而合。
圖源:Enfabrica
Enfabrica 執行長 Rochan Sankar表示:“這不是CXL架構,不是乙太網交換機,也不是DPU——它可以做所有這些事情。這是一類不同的產品,可以解決不同類別的問題。”
據瞭解,Enfabrica的ACF-S採用100%基於標準的硬體和軟體介面,包括原生多埠800千兆乙太網網路和高基數PCIe Gen5和CXL 2.0+介面。該結構可直接橋接和互連GPU、CPU、加速器、記憶體和網路等各種裝置,在這些裝置之間提供可擴充套件、流式、每秒多TB的資料傳輸。它將消除對專用網路互連和傳統機架頂部通訊硬體的需求,充當通用資料移動器,克服現有資料中心的I/O限制。
也就是說,ACF-S無需改變裝置驅動程式之上的物理介面、協議或軟體層,即可在單個矽片中實現異構計算和記憶體資源之間的多TB交換和橋接,同時大幅減少當今 AI 叢集中由機架頂部網路交換機、RDMA-over-Ethernet NIC、Infiniband HCA、PCIe/CXL交換機和連線 CPU的DRAM所消耗的裝置數量、I/O 延遲跳躍和裝置功率。
透過結合獨特的CXL記憶體橋接功能,Enfabrica的ACF-S成為業內首款可為任何加速器提供無頭記憶體擴充套件的資料中心矽產品,使單個GPU機架能夠直接、低延遲、無爭用地訪問本地CXL DDR5 DRAM,其記憶體容量是GPU原生高頻寬記憶體 (HBM) 的50倍以上。
成本也是這家初創公司的賣點之一。這是由於節省了購買NIC和PCIe交換機的費用。據該公司稱,Enfabrica的旗艦ACF交換機矽片使客戶能夠在相同效能點上將大型語言模型 (LLM) 推理的GPU計算成本降低約50%,將深度學習推薦模型 (DLRM) 推理的GPU計算成本降低75%。
3.2Tbps超高速,實現50多萬GPU互連
2024年11月19日,在超級計算 2024 (SC24) 大會上,Enfabrica宣佈其突破性的3.2太位元/秒 (Tbps) ACF SuperNIC晶片“Millennium”及其相應的試點系統 Thames全面上市。Millennium為 GPU 伺服器提供多埠 800 千兆乙太網連線,頻寬和多路徑彈性是業內任何其他 GPU連線網路介面控制器 (NIC) 產品的四倍。Enfabrica晶片將於2025年第一季度開始批次供貨。

圖源:Enfabrica
Millennium具有高基數、高頻寬和併發 PCIe/乙太網多路徑和資料移動功能,可以獨特地在每個伺服器系統中縱向和橫向擴充套件四到八個最新一代 GPU,為 AI 叢集帶來前所未有的效能、規模和彈性。Millennium 還引入了軟體定義的 RDMA 網路,將傳輸堆疊控制權交給資料中心運營商,而不是 NIC 供應商的韌體,而不會影響線速網路效能。
憑藉單個ACF-S晶片上的800、400和100千兆乙太網介面以及32個網路埠和160個PCIe通道的高基數,首次可以使用更高效的兩層網路設計構建超過50萬個GPU的AI叢集,從而實現叢集中所有GPU的最高橫向擴充套件吞吐量和最低的端到端延遲。
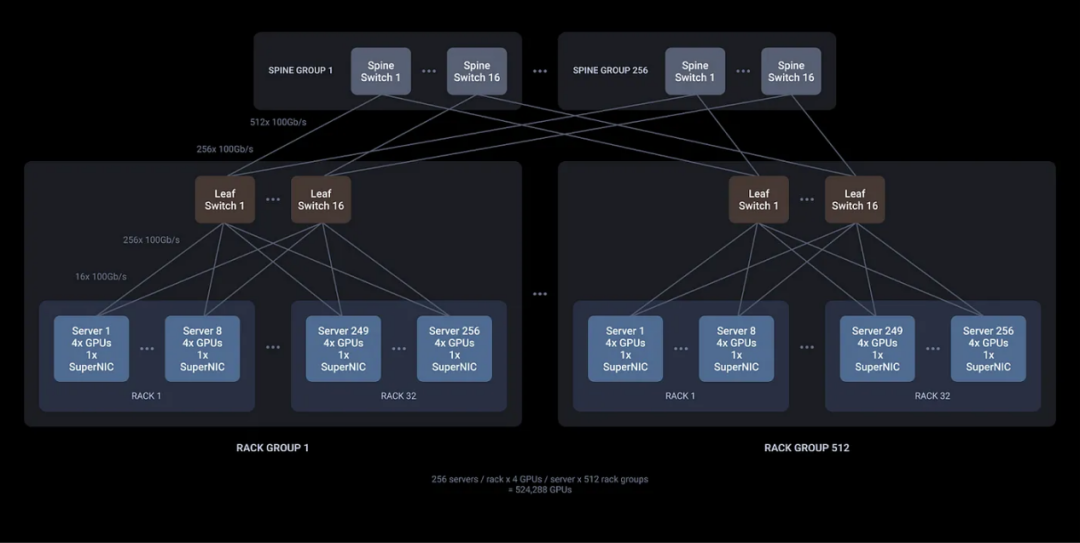
2層500K+ GPU叢集設計(跨所有網路層的完整橫截面頻寬)(圖源:Enfabrica)
Enfabrica相信其互聯技術將成為未來GPU計算網路的核心。Constellation Research Inc. 副總裁兼首席分析師Andy Thurai表示,Enfabrica可以為AI網路領域提供一個有趣的替代方案,目前該領域由 Nvidia 及其 Mellanox 解決方案主導。他解釋說,Enfabrica 的一個顯著差異是它能夠在GPU和CPU之間高速移動資料。
也就說,不僅是GPU,Enfabrica還有望改變CPU的競爭力。Thurai 表示:“這可以讓更多公司探索使用CPU而不是GPU來開發人工智慧,因為GPU目前供應不足。Enfabrica的獨特優勢在於它使用現有的介面、協議和軟體堆疊,因此無需重新連線基礎設施。”
結語
隨著AI模型訓練對效率和成本效益的要求不斷提高,網路的重要性愈發凸顯。據650 Group預測,到2027年,資料中心在計算、儲存和網路晶片高效能I/O領域的矽片支出將翻倍,超過200億美元。這無疑是一塊極具吸引力的市場蛋糕。
英偉達等公司對Enfabrica初創公司的投資,不僅彰顯了對其技術創新的高度認可,更是著眼於未來AI生態戰略佈局的一步棋。要突破當前人工智慧領域面臨的網路I/O瓶頸,離不開應用人工智慧、GPU計算和高效能網路領域的專家之間的創造性工程設計和緊密協作。只有摒棄孤立競爭,形成合力,才能共同推動技術進步,為行業注入新動力。
END
相關文章
- 一加Ace 5魔改驍龍8 Gen3:在晶片層級進行系統重構
- 英偉達核彈來了!RTX 5090售價再次曝光:想買準備2萬預算
- 英偉達投資了一家晶片“競爭對手”
- 博世將全球裁員5500人:競爭及價格壓力持續加劇,汽車行業面臨嚴重產能過剩
- 獲獎希望多大?鄭欽文競爭2024年度最佳運動員,再遇最大“剋星”
- 英偉達漲幅不小!RTX 5090售價曝光:國行至少1萬5了
- 美企爭相擁抱太陽能:Meta、谷歌、亞馬遜等巨頭引領,掀起清潔能源投資狂潮
- 訊息稱晶片製造商鎧俠12月18日上市,將透過IPO籌資總計約32.85億元
- 微軟支援的矽谷初創企業d-Matrix首款AI晶片開始出貨
- 張蘭爆料自己是李庚希的乾媽 李庚希一家參加過大s與汪小菲的婚禮