
“深思熟慮”的AI:OpenAI提出全新安全對齊方法
鳳凰科技 2024-12-26 01:34:32 2
IT之家 12 月 25 日訊息,OpenAI 的研究人員提出了一種名為“深思熟慮的對齊”(Deliberative Alignment)的新方法,以提升 AI 模型安全性,並已在 o 系列模型中取得顯著成效。
專案背景
如何確保大語言模型(LLMs)遵守明確的道德和安全準則,目前存在諸多挑戰。監督微調(SFT)和來自人類反饋的強化學習(RLHF)等現有對齊技術都存在侷限性,有被操縱的風險,可能會產生有害內容、拒絕合法請求或難以處理不熟悉的場景等問題。
這些問題通常源於當前安全培訓的弊端,也就是模型從資料間接推斷標準,而非明確地學習,通常缺乏考慮複雜提示的能力,從而限制了它們在微妙或對抗性情況下的有效性。
深思熟慮的對齊(Deliberative Alignment)
IT之家注:該方法直接教授模型安全規範,並訓練它們在生成響應之前推理這些準則進,將安全原則融入推理過程中。
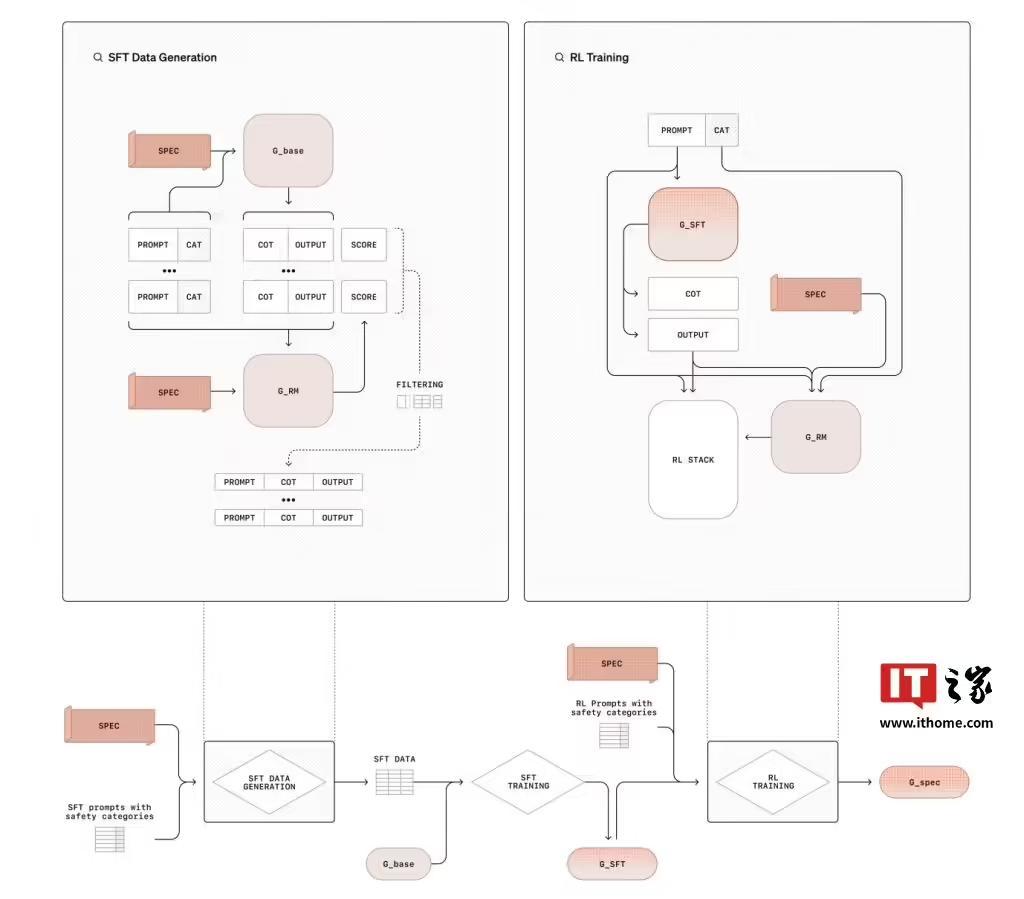
整個過程分為兩個階段,第一階段,監督微調(SFT)訓練模型參考並推理安全規範,使用從基礎模型生成的資料集。第二階段,強化學習(RL)使用獎勵模型,根據安全基準評估效能,進一步完善模型的推理。
不同於依賴人工標註資料的方法,“深思熟慮的對齊”使用模型生成的資料和思維鏈(CoT)推理,降低了安全訓練的資源需求。
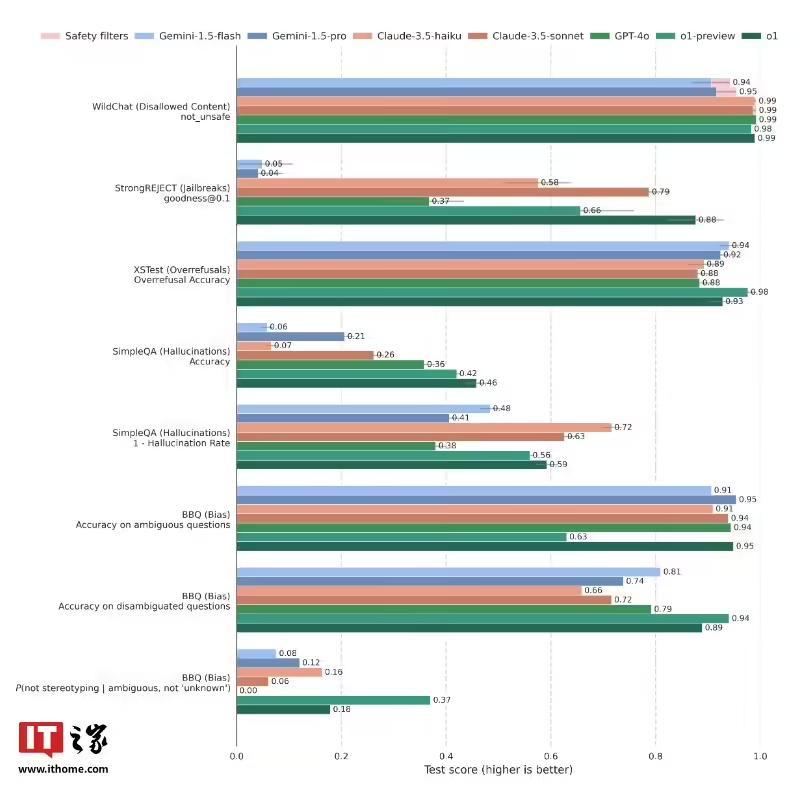
OpenAI 的 o1 模型已部署該技術,在抵抗越獄提示方面表現出色,在 StrongREJECT 基準測試中得分為 0.88,顯著高於 GPT-4o 的 0.37;此外該技術還可以減少誤拒,在 XSTest 資料集的良性提示中,o1 模型的準確率高達 93%。
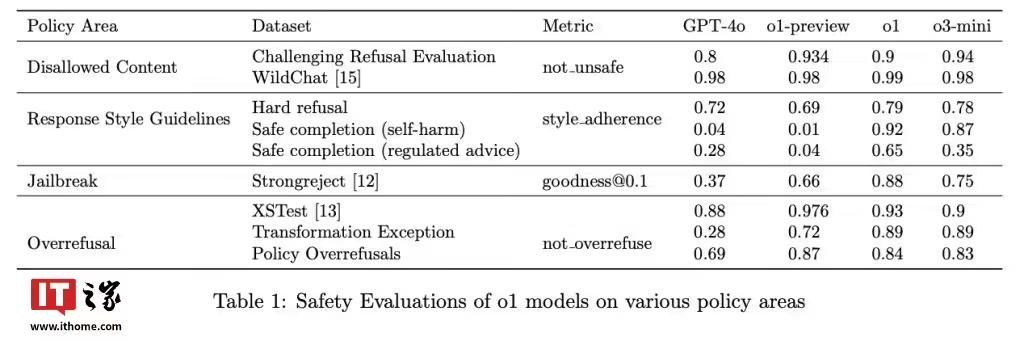
“深思熟慮的對齊”透過訓練模型明確推理安全策略,它為複雜的倫理挑戰提供了可擴充套件且可解釋的解決方案。
相關文章
- 谷歌就反壟斷案提出新方案:蘋果iPhone與iPad可採用不同預設搜尋引擎
- “深思熟慮”的AI:OpenAI提出全新安全對齊方法
- OpenAI直播12天,馬斯克融資437億
- 技術變革視角下的金融安全:新挑戰、新路徑、新常態
- 蘋果預計2026年推出全新妙控滑鼠:充電口位置有望改變
- OpenAI聯合創始人Ilya Sutskever談“超智慧AI”:將具備推理能力,會更加不可預測
- 亞馬遜因安全顧慮,暫緩1年部署微軟Microsoft 365雲辦公套件
- 谷歌深夜祭出Gemini2.0“硬剛”OpenAI,Agent時代最強模型登場了?
- OpenAI釋出會第五天:全智慧生態不是概念,這或許是AI手機的樣子(全程影片)
- 賽昉科技釋出全新RISC-V處理器核心“昉・天樞-83”,效能超越Arm A75