谷歌Agent首次發現真實世界程式碼漏洞!搶救全球數億裝置,或挽回數十億美元損失?
鳳凰科技 2024-11-03 01:31:52 13

LLM居然在真實世界的程式碼中,發現了一個漏洞?
想象一下,AI正在默默地守護著我們日常使用的軟體。忽然,它發現了一個你我可能從未察覺的安全隱患,並且悄無聲息地把它修復了!
就在剛剛,谷歌的Big Sleep專案揭示了一個驚人的成果:一個真實世界的安全漏洞,出現在全球廣泛使用的SQLite資料庫中,而這個漏洞竟然被AI成功識別出來了?在真實世界的危機擴散之前,它及時挽回了局面。
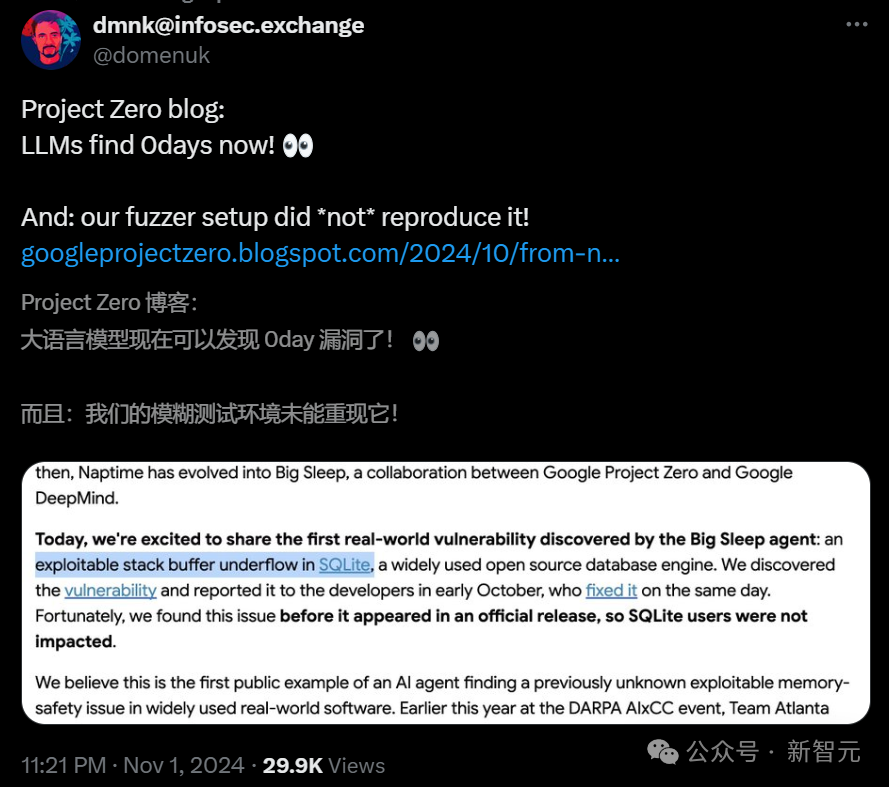
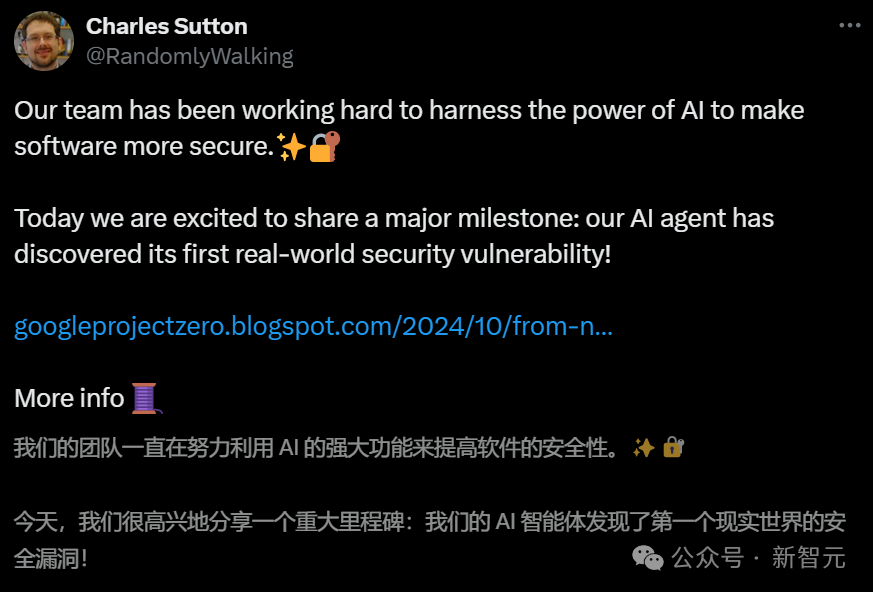
隸屬於谷歌Project Zero和Google DeepMind的團隊聲稱,這是AI Agent在廣泛使用的現實軟體中,發現未知可利用記憶體安全問題的第一個公開示例。

要知道,這不僅僅是一個崩潰的測試用例,它是AI首次在真實世界的軟體中找到未知的、可利用的記憶體漏洞。
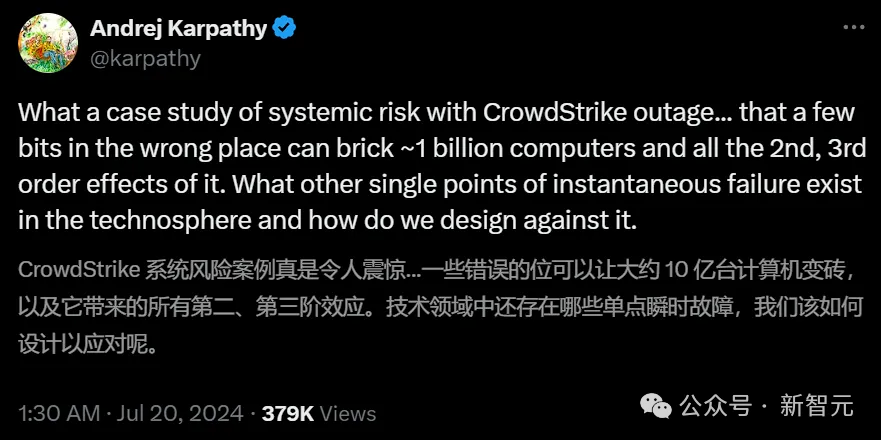
此前,網路安全巨頭CrowdStrike鬧出的一個由「C-00000291*.sys」配置檔案觸發的系統邏輯錯誤,瞬間就破壞掉全世界約10億臺計算機,直接導致微軟藍色畫面、全球停擺。
如果未來某一天,AI能幫我們解決所有技術領域的單點瞬時故障,不知會幫人類節省下多少財富?
用LLM在真實世界中「捉蟲」
隨著LLM程式碼理解和一般推理能力的提高,谷歌研究者一直在探索這些模型如何在識別和演示安全漏洞時,重新人類安全研究人員的方法。
在《Project Naptime:評估大型語言模型的攻防能力》中,Big Sleep團隊介紹了一個利用LLM輔助的漏洞研究框架,並透過在Meta的CyberSecEval2基準測試上提升了最新的效能,展示了這種方法的潛力。

從那時起,Naptime就變成「Big Sleep」,成為了Google Project Zero與Google DeepMind的合作專案。
就在剛剛,谷歌研究者激動地表示,Big Sleep Agent發現了首個真實世界漏洞:一個存在於SQLite中的可利用棧緩衝區下溢漏洞。
SQLite是一款被廣泛使用的開源資料庫引擎。
在十月初,Agent發現了了這個漏洞,於是谷歌研究者立刻將其報告給了開發者,他們在同一天進行了修復。
幸運的是,AI在這個問題出現在官方釋出版本之前,就發現了它,因此SQLite的使用者未受影響。
要知道,SQLite作為輕量級嵌入式資料庫,廣泛應用於智慧手機、瀏覽器、嵌入式系統、IoT裝置等多種環境,涵蓋了許多使用者和敏感資訊。
如果攻擊者利用該漏洞進行資料洩露、系統入侵或破壞,潛在損失金額可能少則幾百萬,多則數十億美元!

谷歌研究者表示,這是AI Agent首次在廣泛使用的真實世界軟體中發現未知的、可利用的記憶體安全問題的公開案例。
之所以會有這次嘗試,是因為今年早些時候,在DARPA的AIxCC活動中,亞特蘭大團隊在SQLite中發現了一個空指標取消引用的漏洞,這就給了谷歌研究者啟發——
是否可以使用SQLite進行測試,看看能否找到更嚴重的漏洞呢?
果然,AI Agent真的找出了一個漏洞。
這項工作,無疑具有巨大的潛力。
在軟體尚未釋出前就發現漏洞,就意味著攻擊者沒有機會利用:漏洞在他們有機會使用之前,就已被修復。
雖然模糊測試也能帶來顯著的幫助,但我們更需要的是一種方法,幫助防禦者找到那些很難透過模糊測試發現的漏洞。
現在,AI有望縮小這一差距!
谷歌研究者表示,這是一條有希望的道路,能為防禦者帶來不對稱的優勢。
因為這個漏洞相當有趣,而且SQLite的現有測試基礎設施(包括OSS-Fuzz和專案自身的測試)並沒有發現它,因此谷歌研究者進行了深入調查。
方法架構
Naptime和Big Sleep專案的關鍵驅動因素,就是已經發現並修補的漏洞變種,仍在現實中不斷被發現。
顯而易見,fuzzing(模糊測試)並不能成功捕獲此類變種漏洞,而對攻擊者而言,手動變種分析的方法仍然價效比很高。
谷歌研究者認為,相比更為寬泛的開放式漏洞研究問題,這種變種分析任務更適合當前的LLM。
透過提供一個具體的起點——比如此前修復的漏洞的詳細資訊——我們就可以降低漏洞研究中的不確定性, 並且還能從一個明確的、有理論支撐的假設出發:「這裡曾經存在一個漏洞,很可能在某處還存在類似的問題」。
目前,他們的專案仍處於研究階段,正在使用帶有已知漏洞的小型程式來評估研究進展。
最近,他們決定透過在SQLite上開展首次大規模的真實環境變種分析實驗,來測試他們的模型和工具鏈。
他們收集了SQLite repository近期的一系列提交,手動篩除了無關緊要的改動和純文件更新。
隨後,他們調整了prompt,為AI Agent同時提供了提交資訊和程式碼變更,並要求它審查當前程式碼庫(在HEAD位置)中可能仍未修復的相關問題。
Project Naptime
Naptime採用了一種專門的架構來增強大語言模型進行漏洞研究的能力,其核心是AI Agent與目的碼庫之間的互動。
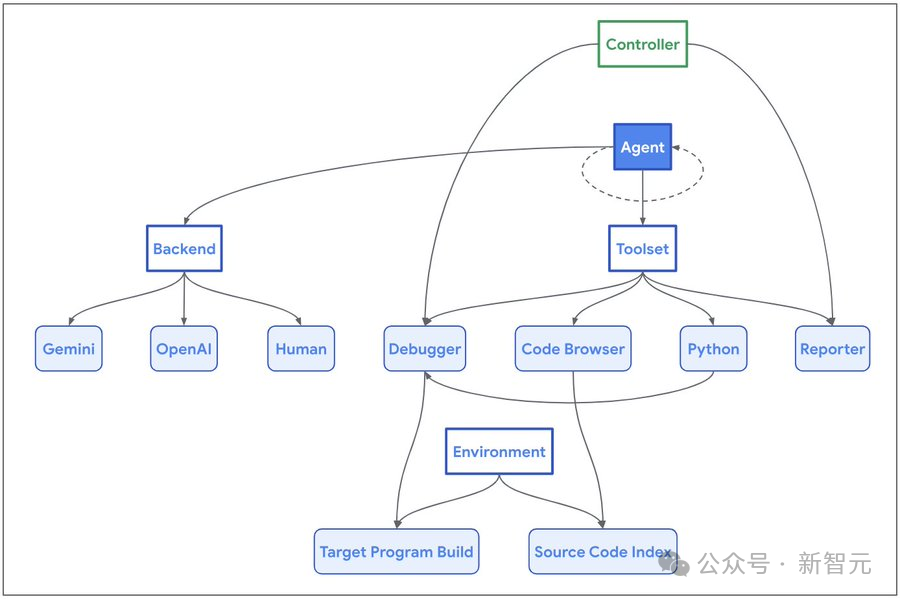
系統架構
為了讓AI Agent可以模仿人類安全研究員的工作流程,研究團隊開發了一系列專用的工具:
程式碼瀏覽工具(Code Browser)使AI Agent能夠瀏覽目的碼庫,這與工程師使用Chromium Code Search的方式類似。它提供了檢視特定實體(如函式、變數等)原始碼的功能,並能識別函式或實體被引用的位置。
Python工具讓AI Agent能夠在隔離的沙盒(Sandbox)環境中執行Python指令碼,用於執行中間計算並生成精確而複雜的目標程式輸入。
偵錯程式工具(Debugger)為AI Agent提供了程式互動能力,可以觀察程式在不同輸入下的行為表現。它支援斷點設定並能在斷點處評估表示式,從而實現動態分析。
報告工具(Reporter)為AI Agent提供了一個結構化的進度通報機制。AI Agent可以傳送任務完成訊號,觸發控制器驗證是否達成成功條件(通常表現為程式崩潰)。當無法取得進一步進展時,它還允許AI Agent主動中止任務,避免陷入停滯狀態。
發現漏洞
這個漏洞非常有趣,比如在一個通常為索引型別的欄位iColumn中,使用了一個特殊的哨兵值-1:
7476: struct sqlite3_index_constraint {7477: int iColumn; /* Column constrained. -1 for ROWID */7478: unsigned char op; /* Constraint operator */7479: unsigned char usable; /* True if this constraint is usable */7480: int iTermOffset; /* Used internally - xBestIndex should ignore */7481: } *aConstraint; /* Table of WHERE clause constraints */
這種模式產生了一個邊緣案例,所有使用該欄位的程式碼都需要正確處理這種情況,因為按照常規預期,有效的列索引值應該是非負的。
seriesBestIndex函式在處理這個edge case時存在缺陷,當處理包含rowid列約束的查詢時,導致寫入了帶有負索引的堆疊緩衝區。
在研究者提供給AI Agent的編譯版本中,debug assertion功能已啟用,這種異常情況會被第706行的斷言檢查所捕獲:
619 static int seriesBestIndex(620 sqlite3_vtab *pVTab,621 sqlite3_index_info *pIdxInfo622 ){...630 int aIdx[7]; /* Constraints on start, stop, step, LIMIT, OFFSET,631 ** and value. aIdx[5] covers value=, value>=, and632 ** value>, aIdx[6] covers value<= and value< */633 const struct sqlite3_index_constraint *pConstraint;...642 for(i=0; inConstraint; i++, pConstraint++){643 int iCol; /* 0 for start, 1 for stop, 2 for step */644 int iMask; /* bitmask for those column */645 int op = pConstraint->op;...705 iCol = pConstraint->iColumn - SERIES_COLUMN_START;706 assert( iCol>=0 && iCol<=2 );707 iMask = 1 << iCol>...713 if( pConstraint->usable==0 ){714 unusableMask |= iMask;715 continue;716 }else if( op==SQLITE_INDEX_CONSTRAINT_EQ ){717 idxNum |= iMask;718 aIdx[iCol] = i;719 }720 }
然而,在釋出版本中,這個斷言檢查並不存在。
在研究者的測試環境中(具體表現會因編譯器和最佳化級別而異),第718行的後續寫入操作會越界寫入aIdx緩衝區下方的記憶體區域,導致pConstraint指標的最低有效32位被破壞。
當這個被破壞的指標在迴圈的下一次迭代中被取消引用時,就會產生潛在的可利用漏洞條件。
不過,即使有了這樣的漏洞說明,對於人類研究員來說,要精確理解如何觸發這個漏洞仍然不易。
雖然針對ROWID列設定約束顯然是個不錯的切入點,但要完全理解,還需要深入研讀程式碼。
而 AI 智慧體似乎已經掌握了比人類研究員更多的SQLite相關知識,這使它能夠更高效地定位問題!
這種情況的一個典型例子,就是LLM在生成測試用例時會直接使用generate_series虛擬表。
(雖然研究者也觀察到模型會先研究可用的虛擬表的情況,但很明顯,它能夠在這裡直接運用已有的知識)。
執行過程重點分析
在這次基於Gemini 1.5 Pro的成功測試中,seed commit為 [1976c3f7],這是一個規模較大、複雜的程式碼變更。
而研究者的AI Agent發現的漏洞,與該seed commit中的變更僅存在鬆散關聯——這種情況在手動變種分析中較為常見,因為在理解程式碼庫中的某個漏洞時,研究人員往往會由此發現其他潛在問題。
以下是關鍵節點摘要,其中,所有ASSISTANT塊中的內容均直接來自AI Agent。
AI Agent對差異中的變化進行了合理的評估,並以此作為研究的切入點:
ASSISTANT
透過引入termFromWhereClause函式,CL改進了在虛擬表查詢中處理OR分支共享的WHERE條件的方式。該函式在考慮巢狀子句的情況下,從WhereClause中檢索特定的條件。
在此更改之前,由於條件索引對映不正確,共享的條件可能未被正確處理,可能導致低效的查詢計劃或錯誤的結果。
最可能出現的問題涉及在allocateIndexInfo和whereLoopAddVirtualOne函式中不正確地處理WHERE子句約束,其中 CL 修改瞭如何使用新的輔助函式來處理約束偏移量。
我將首先檢查allocateIndexInfo函式。
在經過數個步驟探索相關程式碼後,AI Agent形成了一個更明確的測試假設——它試圖透過執行patch中測試用例的修改版本來驗證這個假設,但未能成功。
原因在於patch中的測試用例依賴於一個在當前配置環境中未啟用的擴充套件模組:
TOOL(debugger_run )
程式在未崩潰或命中斷點的情況下退出。退出程式碼為1。
STDERR輸出為:
Runtime error near line 2: no such module: tcl
Parse error near line 3: no such table: x1
ASSISTANT
程式終止是因為TCL模組不可用。測試依賴於TCL虛擬表模組,需要在編譯SQLite時啟用該模組。提供的程式的輸入基於bestindexC.test檔案,它使用TCL模組來測試虛擬表的最佳索引選擇。
為了解決這個問題,需要更改程式輸入,使用不需要TCL模組的其他虛擬表。然而,該漏洞與虛擬表的查詢計劃有關,所以我們仍然需要一個虛擬表來觸發此問題。
我將使用code_browser_source工具來檢索SQLite中的內建虛擬表示例。然後,我將調整輸入,使用其中一個虛擬表,並重新在whereLoopAddVirtualOne中設定斷點。
AI Agent很好地應對了這個問題,準確識別出了修復測試用例所需的各個步驟,並在後續幾個步驟中成功收集到了所有構建測試用例所需的資訊,最終實現了觸達whereLoopAddVirtualOne的目標:
ASSISTANT
sqlite3_create_module函式用於註冊虛擬表模組。shell.c檔案包含了多個這樣的例項,包括generate_series、fsdir、completion和expert模組。其中json表的實現也很值得關注。
我首先關注的是generate_series,然後構造出一個使用該模組的查詢,從而觸發錯誤的約束處理。
需要注意的是,在最初發現和復現該漏洞時,AI Agent對於它試圖觸發的「不正確約束處理」的描述相當模糊。
在這種情況下,完整的執行軌跡讀起來頗似人類研究員的思維過程——從一個想法開始,在調查過程中產生其他幾個想法,最終生成了一個可以復現略有不同漏洞的測試用例。
在本例中,當whereLoopAddVirtualOne在generate_series表上被呼叫時,執行流程最終會進入seriesBestIndex,在那裡約束確實被錯誤處理了。
特別有趣的是,一旦程式崩潰,模型會在解釋問題時表現得更為出色——在生成根因分析(root-cause analysis)和完整崩潰報告時,我們可以看到AI Agent清晰地構造了一個測試用例來觸發特定的已識別邊緣案例:
ASSISTANT
相關的欄位是sqlite3_index_constraint結構體中的iColumn。該欄位表示約束的列編號。要導致斷言失敗,我們需要對索引大於3或小於-1的列設定約束。
讓我們構建一個涉及這些列約束的SQL查詢。generate_series表有名為value、start、step和stop的列。它們的索引是:
- value: 0
- start: 1
- step: 2
- stop:3
要觸發此漏洞,我們可以對ROWID施加一個約束,並對ROWID的約束使用iColumn = -1。
示例查詢如下:
SELECT * FROM generate_series(1,10,1) WHERE ROWID = 1;
該查詢將導致seriesBestIndex函式崩潰。
最終,得到了一個清晰準確的問題總結,幾乎可以直接用於漏洞報告!
TOOL(debugger_run)
程式崩潰:SIGABRT at :0
STDERR輸出為:
sqlite3: src/shell.c:6816: int seriesBestIndex(sqlite3_vtab *, sqlite3_index_info *): Assertion `iCol>=0 && iCol<=2' failed.
ASSISTANT(report_success)
程式在執行SELECT * FROM generate_series(1,10,1) WHERE ROWID = 1;時因seriesBestIndex函式中的斷言失敗而崩潰。
斷言assert(iCol>=0 && iCol<=2)失敗的原因是sqlite3_index_info結構體中的iColumn欄位可能包含超出列索引有效範圍的值,例如在約束涉及ROWID時為-1。
這導致iCol被計算為-2,從而導致斷言失敗。
關於模糊測試
一個顯而易見的問題是:為什麼傳統的模糊測試沒有更早發現這個漏洞?
答案就在模糊測試工具鏈的配置上。
OSS-Fuzz使用的工具並沒有啟用generate_series擴充套件,而替代的fuzzingshell.c工具包含的是舊版本的seriesBestIndex函式,未受此漏洞影響。
雖然SQLite AFL倉庫中包含一個針對研究者提供給Big Sleep智慧體的、相同CLI二進位制檔案的模糊測試配置,但似乎並未被廣泛使用。
這個漏洞是否真的容易發現?
為此,研究者嘗試透過模糊測試重新發現它。
他們遵循SQLite文件中的模糊測試說明,並使用CLI目標。在啟動AFL執行之前,他們還驗證了模糊測試語料庫中包含所需的generate_series和rowid關鍵字。
然而,經過150個CPU小時的模糊測試,問題仍未被發現。
隨後,他們嘗試透過將必要的關鍵字新增到AFL的SQL字典中,來簡化模糊測試的任務。
然而,似乎只有當語料庫包含與導致崩潰的輸入非常接近的示例時,漏洞才能被快速發現,因為程式碼覆蓋率對這個特定問題並不是可靠的指標。
誠然,AFL並不是針對像SQL這種基於文字的格式最適合的工具,大多數輸入在語法上無效,會被解析器拒絕。
然而,如果將這一結果與Michal Zalewski在2015年關於模糊測試SQLite的部落格文章進行比較,會發現十分有趣的事。
那時,AFL在發現SQLite漏洞方面相當有效;經過多年的模糊測試,該工具似乎已經達到自然的飽和點。
雖然研究者迄今為止的結果與AFL釋出時帶來的顯著效果相比顯得微不足道,但它有自己的優勢——有機率能夠有效地發現一組不同的漏洞。
結論
對於團隊來說,這個專案無疑成功了。
在廣泛使用且模糊化的開源專案中找到漏洞,非常一個令人興奮!
這也就意味著:當提供正確的工具時,當前的LLMs可以進行漏洞研究。
不過,研究者想重申,這些都是高度實驗性的結果。
Big Sleep 團隊表示:目前,在發現漏洞方面,針對特定目標的模糊器可能至少同樣有效。
研究者希望,未來這項工作將為防禦者帶來顯著優勢——
不僅有可能找到導致崩潰的測試用例,還能提供高質量的根本原因分析,使得問題的分類和修復變得更便宜且更有效。
谷歌研究者表示,會繼續分享自己的研究成果,儘可能縮小公共技術前沿和私有技術前沿之間的差距。
Big Sleep團隊也會將繼續努力,推進零日計劃的使命,讓0-day變得更加困難。
團隊介紹

Dan Zheng

團隊中唯一的華人Dan Zheng是谷歌DeepMind的研究工程師,從事程式碼和軟體工程的機器學習,以及程式語言的研究。
此前,他曾參與Swift for TensorFlow的工作,專注於Swift中的可微分程式設計。
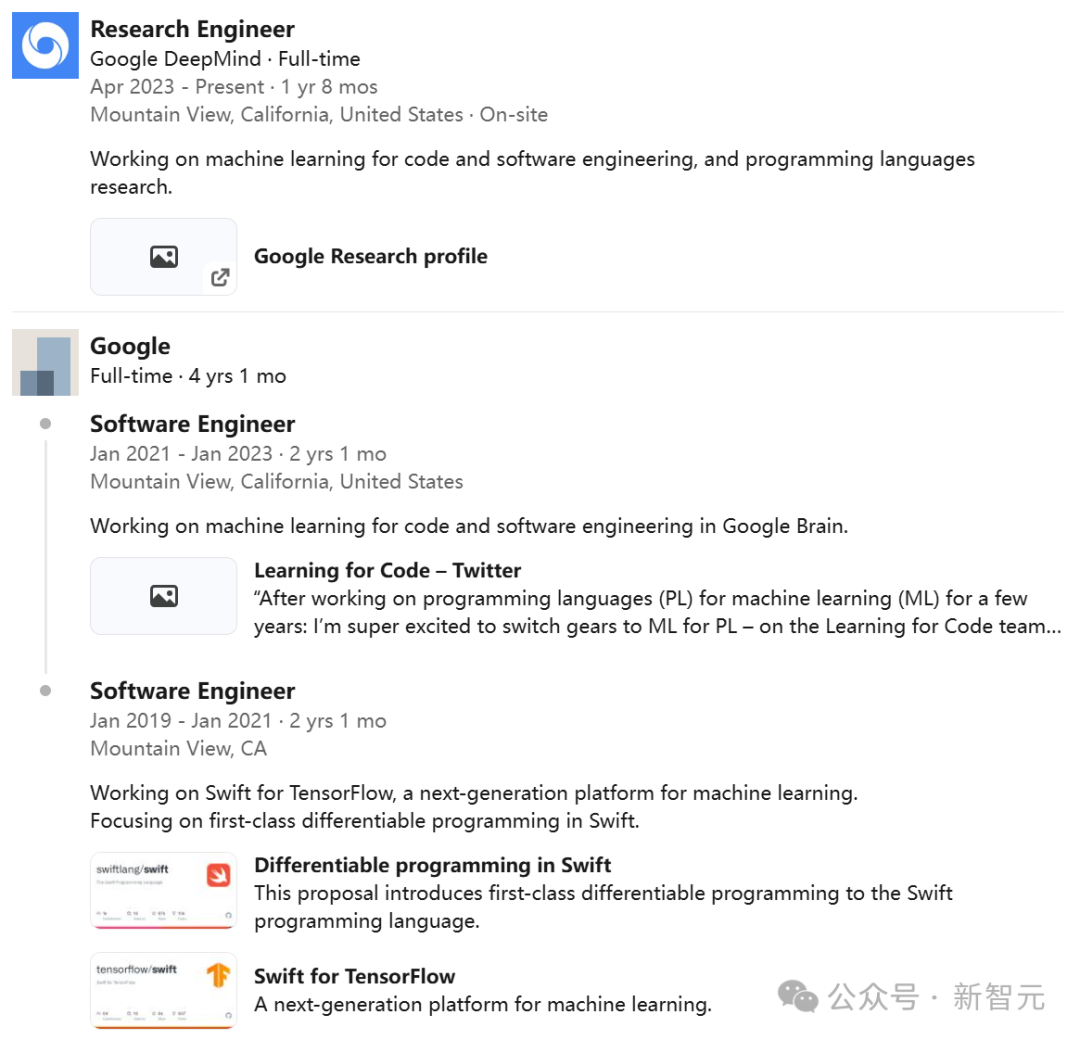
他在普渡大學獲得了電腦科學專業的學士學位。畢業後,他做了多年的學生研究員,期間研究成果頗豐。