
AI影片大模型Vidu 1.5釋出:首發“多主體一致性”,能理解記憶上下文
鳳凰科技 2024-11-14 01:35:58 3

作者 | ZeR0
編輯 | 漠影
智東西11月13日報道,今日,國內影片大模型創企生數科技釋出Vidu 1.5新版本。該版本全新上線“多圖參考”功能,突破了“一致性”難題,具備涵蓋人物、物體、環境等融合的多主體一致效能力。
透過上傳1~3張參考圖,Vidu 1.5可實現對單主體100%的精確控制,同時實現多主體互動控制、主體與場景融合控制,能夠無縫整合人物、道具和場景。
在擁有處理更復雜任務能力的同時,Vidu 1.5延續了其業界領先的生成效率,不到30秒即可生成一段影片。
今日上新的Vidu 1.5版本首次展現出上下文學習的能力,告別了單點微調,體現出視覺模型與語言模型一樣,在經過充分的訓練後,具備對上下文的深刻理解、記憶等能力。這也標誌著視覺模型進入全新的“上下文”時代。
直通車:www.vidu.studio
一、三大技術突破加成,攻克“多主體一致性”難題
影片生成的一個難題是“一致性控制”問題,即在不同的生成影片之間,模型往往難以確保主體的外觀、特徵、風格保持一致。尤其是在處理包含多個角色或物理的場景時,模型很難做到對多個主體同時控制,主體間的互動也難以保持自然連貫。
Vidu自上線以來就致力於解決“一致性”核心難題,起初具備“角色一致性”生成能力,確保了人物面部特徵的一致性;9月又在全球率先發布了“主體一致性”功能,實現角色全身形象一致。此次“多圖參考”進一步強化了Vidu在一致性方面的優勢。
據介紹,目前除了Vidu,其他影片生成模型都無法有效控制面部一致性。少數模型透過大量相似圖片的輸入進行成本高昂的單點微調,才能實現基本的面部一致性。
Vidu直接提升了整體影片模型的可控性,透過靈活的多元輸入實現了多角度、多主體、多元素的一致性生成。其技術突破具體體現在以下三個方面:
1、複雜主體的精準控制:無論是細節豐富的角色,還是複雜的物體,都能保證其在多個不同視角下的一致性。比如造型複雜的3D動畫風格角色,在各種刁鑽視角下,都能確保頭型、服飾等細節一致。
2、人物面部特徵和動態表情的自然一致:在人物特寫畫面中,能確保人物面部特徵細節和表情變化自然流暢,不會出現面部僵硬或失真現象。
3、多主體一致性:Vidu支援上傳多個主體影象,包括人物角色、道具物體、環境背景等,並在影片生成中實現這些元素的互動。例如,使用者可以上傳主體、客體和環境的圖片,建立定製角色身穿特定服裝、在定製空間內自由動作的場景。Vidu還支援多個主體之間的互動,使用者可以上傳多個自定義角色,讓它們在指定空間內進行互動。此外,Vidu支援融合不同主體特徵,例如將角色A的正面與角色B的反面無縫融合,創造出全新的角色或物體。
據生數科技分享,以上這些能力目前業界其他影片模型均無法實現。
二、省去“煉丹”環節,一款“LoRA終結器”
上述突破性的工作源自於Vidu 1.5背後基礎模型能力的全面提升,而非業界主流的LoRA微調方案,無需專門的資料採集、資料標註、微調訓練環節,一鍵直出高一致性影片。
此前LoRA微調一直是業界解決一致性問題的主流方案。LoRA(Low-Rank Adaptation)方案,即在預訓練模型的基礎上,用特定主體的多段影片進行微調,讓模型理解該主體的特徵,從而能生成該主體在不同角度、光線和場景下的形象,保證其在若干次不同生成時的一致性。
比如創作一隻卡通狗的形象,想生成連續一致的影片畫面,但模型在預訓練過程中並沒有學習過該形象,所以需要拿卡通狗的多段影片,讓模型進一步訓練,直到認識這隻卡通狗長什麼樣。
但通常LoRA需要20~100段的影片,資料構造繁瑣,且需要一定的訓練時間,通常需要數個小時甚至更久的時間,成本是單次影片生成的成百上千倍。
此外,LoRA微調模型容易產生過擬合,即在理解主體特徵的同時,也會遺忘大量原先的知識。這導致對於動態的表情或肢體動作的變化,很難做到有效控制,容易產生僵硬或不自然的效果。在複雜動作或大幅度變換時,微調模型也無法很好地捕捉細節,導致主體特徵不夠精準。
因此,LoRA主要適用於大多數簡單情形下的主體一致性需求,但對於高複雜的主體或問題場景,需要更多的微調資料和更復雜的模型微調策略。
而Vidu 1.5基於通用模型能力的提升,僅靠三張圖就實現高可控的穩定輸出,直接省去“煉丹”環節,堪稱是“ LoRA終結器”。
三、視覺模型進入“上下文時代”
要實現類似的多主體一致性生成任務,需要模型能夠同時理解“多圖的靈活輸入”,不僅是數量上的多圖,還要圖片不侷限於特定的特徵。
這與語言模型的“上下文學習”能力具有顯著的相似性。
在語言模型中,理解上下文不僅僅是處理單一的文字輸入資訊,而是透過關聯前後的文字、識別語句之間的關係,生成連貫且符合情境的回答或內容。
同樣地,影片生成或多圖生成任務中,模型需要能夠理解多個輸入影象的準確含義和它們之間的關聯性,以及能夠根據這些資訊生成一致、連貫且有邏輯的輸出。
秉承通用性的理念,Vidu有和大語言模型一致的設計哲學:
1、統一問題形式:大語言模型將所有問題統一為(文字輸入,文字輸出),Vidu則將所有問題統一為(視覺輸入,視覺輸出);
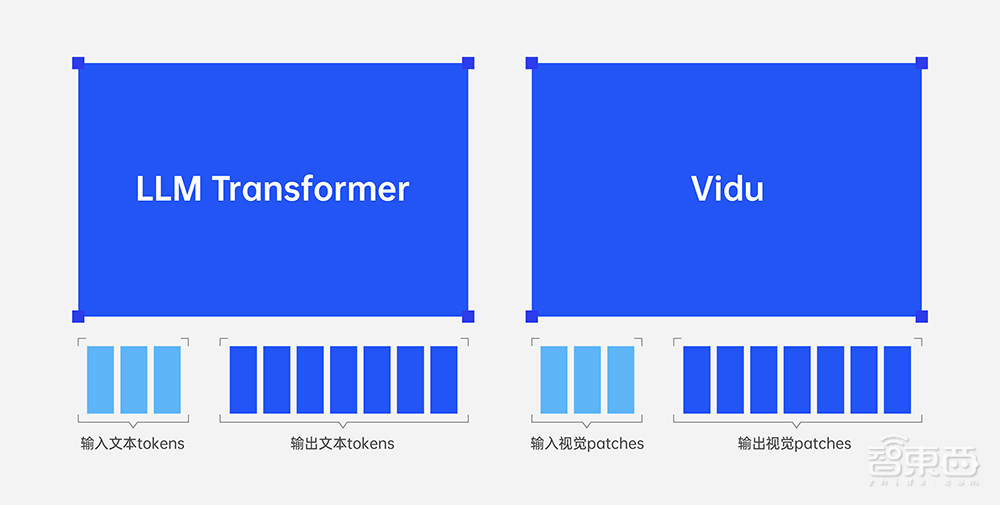
2、統一架構:大語言模型和Vidu均用單個Transformer統一建模變長的輸入和輸出;
3、壓縮即智慧:大語言模型從文字資料的壓縮中獲取智慧,Vidu從影片資料的壓縮中獲取智慧。
透過不斷擴充套件上下文長度,Vidu從1.0迭代到1.5後出現了智慧湧現效應,模型能夠透過視覺上下文完成大量新任務的直接生成。從單輸入主體的文/圖生影片,到多輸入參考資訊,未來生數科技還將以更長、更豐富的上下文作為輸入,進一步提升模型的能力表現。
結語:視覺模型將具備更強認知能力
當前的視覺模型儘管在文字生成影片等方面取得顯著進展,但與語言模型在深層次智慧上的突破相比,尚存在較大差距。
過往的影片模型如果想實現諸如一致性生成的能力,需要針對每一個場景設計相應的模型進行微調,而無法像語言模型一樣,透過上下文學習基於少量的示例或提示快速適應新任務。
Vidu 1.5則展現了出色的上下文學習能力。這意味著視覺模型不僅具備了理解和想象的能力,還能夠在生成過程中進行記憶管理。
同時,更出色的一致性控制,使Vidu 1.5在創作細膩、逼真的角色時具有顯著優勢,也進一步降低了對生成影片內容進行後期加工最佳化的負擔。