
天工版o1、4o同時上線!超強邏輯推理秒殺數學競賽,實時語音陪聊太上頭
鳳凰科技 2025-01-07 01:33:05 2
【新智元導讀】今天,「天工大模型4.0」o1版/4o版在網頁端和APP端正式上線了,人人可玩的那種。
最近,2024中國網際網路價值榜釋出。
2024年AIGC應用使用者規模TOP榜中,崑崙萬維旗下天工AI強勢入圍!

如今,天工AI已經取得了中國典型工具類AIGC應用TOP 4的好成績,在多梯隊的猛烈廝殺格局中穩穩佔據優勢。
同時,還不斷有好訊息傳來。
就在今天,天工大模型4.0 o1版/4o版正式上線天工網頁端和APP。底座大模型,正式進化到「天工4.0」。
「天工大模型4.0」 o1版(Skywork o1)的上線,意味著國內首款中文邏輯推理能力的o1模型來了!
數學高考題、考研題、奧數題,Skywork o1都能靠自己的逐步思考破解。
注意!Skywork o1並不是簡單地復現OpenAI o1模型的工作。它不僅在模型輸出上內生了思考、計劃、反思等能力,還在模型真正擁有了思考和反思之後,帶來了推理能力的提升。

在最近熱轉的復旦等機構解密OpenAI o1路線圖這一研究中,skywork-o1就被列為國內o1級模型的代表之一
並且,崑崙萬維天工大模型4.0上線後,應用端不僅在邏輯推理和程式碼功能上有了幾大提升,語音互動上的表現也著實令人驚歎。
一個月正式釋出的新產品「實時語音對話助手Skyo」,如今有了史詩級提升。
眾網友實測後紛紛表示,原來國內版的「Her」,已經進化到了不輸OpenAI版本的地步!
具備多語言對話能力的Skyo,不僅能快速響應、主動發起對話、實時打斷,給出的回應還十分情感化,已經具備了類人特徵。

還等什麼,實測馬上呈上。
超強推理+自我反思,免費體驗
現在,分別開啟天工APP或網頁端,任何人皆可免費享用最新天工4.0 4o版或o1版模型加持的AI了。
既然主打的是推理,那麼我們就先來看看Skywork o1在數學題上的表現如何。
體驗地址:https://www.tiangong.cn/o1Chat/055
先來個硬核的,AIME數學競賽題。

題目是這樣的——
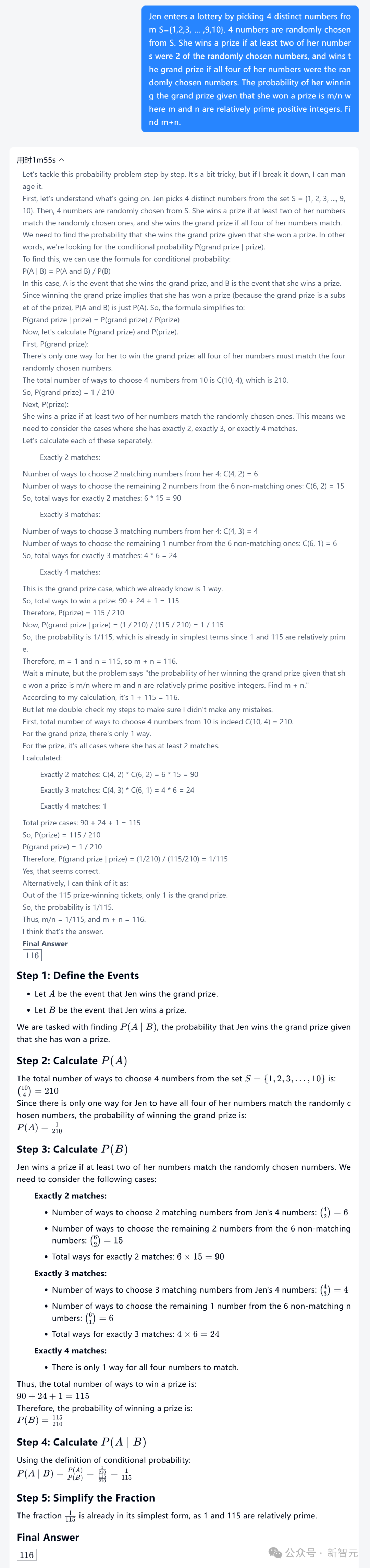
Jen透過從S={1,2,3, ... ,9,10} 中挑選4個不同的數字來參加抽獎。從S中隨機選擇4個號碼。如果她的至少兩個號碼是隨機選擇的號碼中的2個,她就能贏得獎金;如果她的四個號碼都是隨機選擇的號碼,她就能贏得大獎。假設她贏得了獎品,她贏得大獎的機率是m/n,其中m和n是相對質的正整數。求m+n。
Skywork o1用時1分55秒,經過一番思考後,最終給出了正確答案——116。
上下滑動檢視
對於下面這道同樣有些難度的數學題,模型在經過一番思考之後,很快就想到了用圖論中的「圖蘭定理」去解。
值得一提的是,在思考過程中它對答案不確定時,甚至會反思自己的回答,直至最終確定25是正確答案。
一個象棋比賽,共有十名選手參加,每一個選手都需要和其他選手每人下一盤棋,賽程進行到某階段時,發現任意三個選手中,起碼有兩個相互之間還沒有下過一盤棋,此時至多進行了多少場比賽?

上下滑動檢視
2024年高考新課標一卷的數學真題,Skywork o1也能做出正確答案,就是方法稍微「笨」了點。

複雜一些的邏輯推理題,Skywork o1也能做對。
這道從池塘中取水的推理題,它透過一步步的思考過程,推理出了正確答案。

上下滑動檢視
還有這道「一個人花8塊錢買了一隻雞,9塊錢賣掉了,然後他覺得不划算,花10塊錢又買回來了,11塊賣給另外一個人。問他賺了多少」,Skywork o1反覆斟酌之後給出了正確的答案。

上下滑動檢視
為什麼剛出生的小孩只有一隻左眼?這個腦筋急轉彎,沒能瞞過Skywork o1的眼睛。

上下滑動檢視
弱智吧難題,不在話下。
比如父母以後的錢都是留給我的,可不可以認為父母現在正在花我的錢?Skywork o1從財產所有權、繼承權、遺囑和繼承法、道德和家庭關係方面給出了全面的回答。

上下滑動檢視
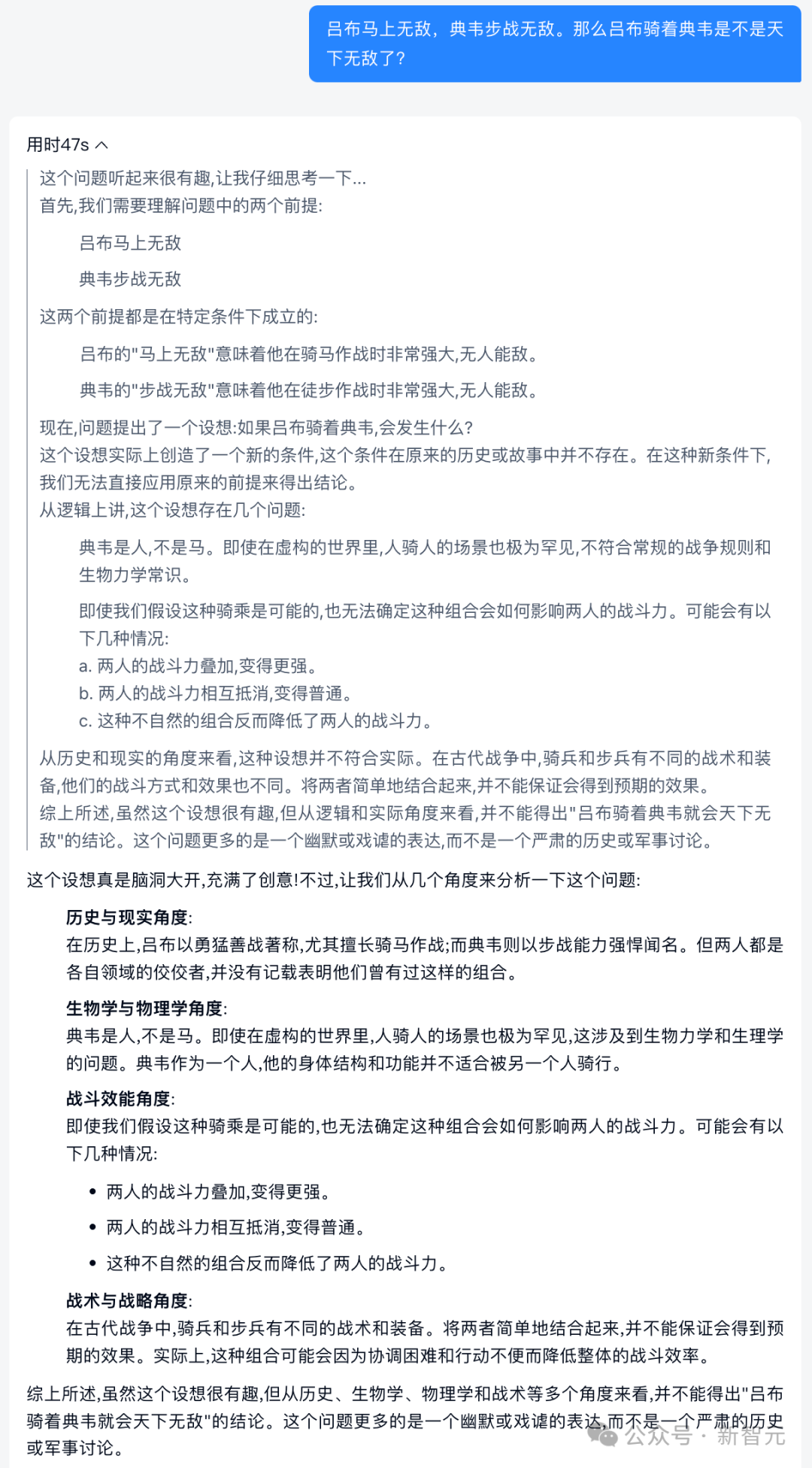
呂布馬上無敵,典韋步戰無敵,呂布騎著典韋會不會天下無敵?Skywork o1表示,有趣的腦洞只是一個戲謔的表達,而非嚴肅的歷史或軍事討論。
上下滑動檢視
最後,上一道LeetCode貪心演算法的分發餅乾程式碼難題。題目如下——
假設你是一位很棒的家長,想要給你的孩子們一些小餅乾。但是,每個孩子最多隻能給一塊餅乾。
對每個孩子i,都有一個胃口值 g[i],這是能讓孩子們滿足胃口的餅乾的最小尺寸;並且每塊餅乾j,都有一個尺寸s[j] 。如果s[j] >= g[i],我們可以將這個餅乾j分配給孩子i,這個孩子會得到滿足。你的目標是儘可能滿足越多數量的孩子,並輸出這個最大數值。
Skywork o1也順利給出了答案。

自研技術方案,持續創新迭代
那麼,Skywork o1為何能在邏輯推理任務上,有如此大幅的提升?
這就要得益於天工三階段自研的訓練方案。
推理反思能力訓練
首先,在推理訓練方面,團隊透過自主研發的多智慧體體系,構建出了高質量的分步推理、反思與驗證資料。
然後,用這些高質量且多樣化的長思考資料,對基座模型進行繼續預訓練和監督微調,並在版本迭代中採用大規模的自蒸餾和拒絕取樣,從而顯著提升了模型的訓練效率和邏輯推理能力。
推理能力強化學習
其次,在強化學習階段,團隊創新性地提出了一種適配分步推理強化的獎勵模型——Skywork o1 Process Reward Model(PRM)。
在最新的版本中,團隊將Skywork-PRM的應用範圍,從原本側重的數學和程式碼領域,拓展到了常識推理、邏輯推演和倫理決策等更廣泛的場景中。同時,還針對寫作、閒聊等通用領域以及多輪對話構建了專門的訓練資料,實現了全場景覆蓋。
此外,團隊重點提升了Skywork-PRM的模組化評估能力,特別是在處理o1風格思維鏈方面,最佳化了試錯和反思驗證機制。透過更細緻的評估體系,為強化學習和搜尋過程提供了更精準的獎勵訊號指導。
推理planning
最後,在推理的規劃方面,團隊透過自研的Q*線上推理演算法,以及模型的線上思考能力,實現了最優推理路徑的尋找。
概括來說,Q*演算法透過借鑑人類大腦中「System 2」的思考方式,將LLM的多步推理過程抽象為一個啟發式搜尋問題。
然後,再透過Q*線上推理框架與模型線上思考的結合,實現了推理過程中的精細規劃,進而指導LLM的解碼過程。
Q*演算法的成功落地,不僅顯著提升了模型的線上推理能力,同時也標誌著Q*演算法的全球首次實現和公開。

論文地址:https://arxiv.org/abs/2406.14283
更進一步的,團隊基於Q*演算法對推理系統進行了全面最佳化。
第一點是模組化的樹形結構推理:
團隊透過高質量、多樣化的長思考資料對Skywork o1進行預訓練和監督微調,使模型具備了對整個推理流程進行系統規劃,自動將回答按層次展開,同時在推理過程中融入自我反思和驗證環節的結構化輸出能力。
此外,還創新性地利用以「模組」為單位的規劃方式,取代了傳統的以「句子」為單位的方法。既提升了規劃效率,也使PRM能夠基於更完整的模組化回答進行準確判斷和推理指導。
第二點是自適應的搜尋資源分配:
針對現有o1風格模型存在的過度思考問題,團隊開發出了一種全新的自適應搜尋資源分配機制。也就是,透過對使用者query進行難度預估,自適應地控制搜尋樹的寬度和深度,進而實現簡單問題快速響應、複雜問題多輪驗證的動態平衡,有效提升了系統的計算效率和回答準確率。
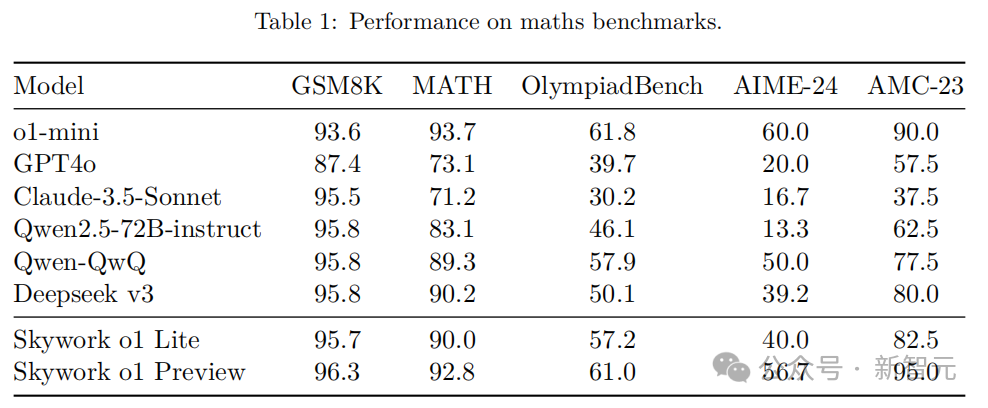
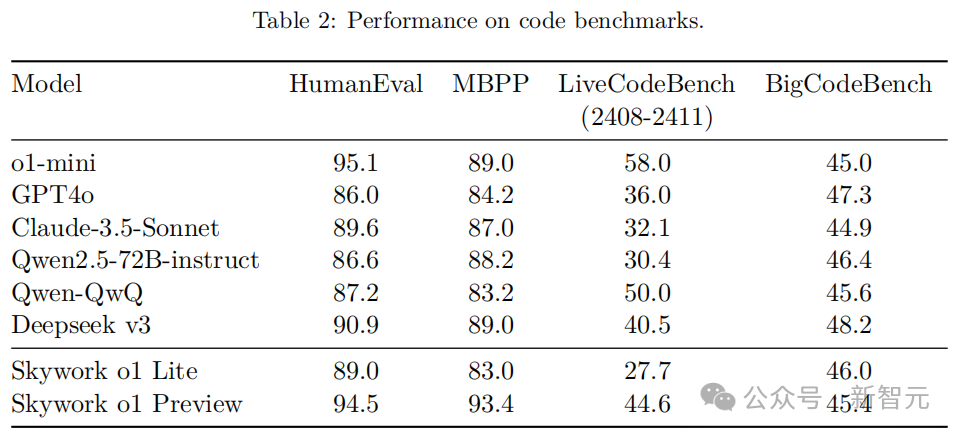
最終,Skywork o1在GSM8k,MATH,OlympiadBench,AIME-24和AMC-23標準數學基準測試,以及HumanEval、MBPP、LiveCodeBench和BigCodeBench程式碼基準測試中,效能顯著優於常規通用大模型,表現僅次於o1-mini。
實時語音助手,開啟AI互動新紀元
在APP端,「天工大模型4.0」4o版加持的實時語音對話助手Skyo,同樣帶來了前所未有的自然互動體驗。
它不僅能在1秒內快速響應,還具備了多語言對話、主動發起對話、實時被打斷的能力。
與此同時,4o未來版本可以支援個性化聲音定製功能,能夠以任何人希望的風格暢聊。
這是這種個性化的體驗,讓4o不再是冰冷的AI,而是一個更智慧的AI夥伴。
當你喚醒Skyo後,他會主動熱情打招呼,並嘗試開啟一個新的話題。當你生活中遇到難題時,可以向它尋求建議和幫助。
比如,家裡2歲的寶寶總是說不要不要,我該怎麼辦?
相關文章
- 崑崙萬維“天工4.0”攜超強o1/4o霸氣上線!強推理+實時語音,免費無限體驗
- 天工版o1、4o同時上線!超強邏輯推理秒殺數學競賽,實時語音陪聊太上頭
- 姜塵語音曝光,投資人曝張頌文家暴出軌、潛規則女演員,公開細節
- 《“騙騙”喜歡你》上線,歡喜冤家的年終盛宴,李雪琴表現驚豔
- 2024HiShorts! 主競賽提名片單公佈!
- 對標3萬元的Vision Pro!vivo MR原型機明年上線:部分體驗已超越蘋果
- AI同時操控200個機器人,任務成功率超90%,半數故障依然“能打”
- 王小川的百川智慧釋出全鏈路領域增強金融大模型,準確率超過GPT-4o
- 斯諾克賽程:2站同時打響,中國4人出戰,丁俊暉張安達衝8強
- 大廠和大廠前高管爭相入局!具身智慧競賽進入下半場